Updated: November 19, 2011
Let's talk debug. So you wrote a piece of code and you want to compile it and run it. Or you have a binary and you just run it. The only problem is, the execution fails with a segmentation fault. For all practical purposes, you call it a day.
Luckily for you, the ultimate combination of the GNU Debugger (gdb) and Dedoimedo tutorials will help you overcome the problem. Today, we will learn how to handle misbehaving binary code, how to examine its execution step by step, how to interpret errors and problems, and we will even step into the assembly code and hunt for problems there. This won't be easy, but it sure will be one of the best super-duper admin guides you have read so far.

Prerequisites
I repeat: this will not be easy. Working with gdb is not something anyone can do at their leisure. There are many requirements you must meet before you can have a successful session.
Sources
You can debug code without having access to source files. However, your task will be more difficult, because you will not be able to refer to the actual code and try to understand if there's any kind of logical fallacy in the execution. You will only be able to follow symptoms and try to figure out where things might be wrong, but not why.
Sources compiled with symbols
On top of that, you will want sources with symbols, so you can map instructions in the binary program to their corresponding functions and lines in the source code. Otherwise, you will be sort of groping in the dark.
Understanding of gdb
This tutorial will teach you a handful of basic and intermediate commands, so you need not worry too much about that. However, if you really find the concepts alien and you struggle with compilations and working on the command line in general, perhaps this topic is a little advanced for you at the moment.
Understanding of Linux system
This is probably the most important element. First, you will need some core knowledge of the memory management in Linux. Then, the fundamental concepts like code, data, heap, stack and whatnot. You should also be able to navigate /proc with some degree of comfort. You should also be familiar with the AT&T Assembly syntax, which is the syntax used in Linux, as opposed to Intel syntax, for example.
All right, if you meet all of the above - or wish to - then you can proceed.
Simple example
We will begin with a simple example - a null pointer. In layman's terms, null pointer is a pointer to an address in the memory space that does not have a meaningful value and cannot be referenced by the calling program, for whatever reason. This will normally lead to an unhandled error, resulting in a segmentation fault.
Here's our source code:

#include <stdio.h>
int main (int argc, char* argv[])
{
int* boom=0;
printf("hello %d",*boom);
}
Now, let's us compile it, with symbols. This is done by using the -g flag when running gcc. We have seen this before, in the Linux Kernel Crash Book examples.

gcc -g source.c -o naughty-file.bin
And then, we run it and get a nasty segmentation fault:

Now, you may want to try to debug this problem using standard tools, like perhaps strace, ltrace, maybe lsof, and a few others. Normally, you would do this, because having a methodical approach to problem solving is always good, and you should start with simple things first. However, I will purposefully not do that right now to keep the mind clobber at a minimum. As we advance in the tutorial, we will see more complex examples and the use of other tools, too.
All right, so now we need to start using the GNU Debugger. We will invoke the program once again, this time through gdb. The syntax is simple:
gdb <program>
And so we do it.

For the time being, nothing happens. The important thing is that gdb has read symbols from our binary. The next step is to run the program and reproduce the segmentation fault. To do this, simply use the command run inside gdb.

We see several important details. One, that separate debuginfo (symbols) for third-party libraries, which are not part of our own code, are missing. This means that we can hook into their execution, but we won't see any symbols. We'll see an example soon. Two, we see that our program crashes. The problem is in the sixth line of source, as shown in the image, our printf line. Does this mean there's a problem with printf? Probably not, but something in the variable that printf is trying to use, most likely. The plot thickens.
What we learn here is that we have symbols, that gdb won't run automatically and that we have a meaningful way of reproducing the problem. This is very important to remember, but we will recap this when we discuss when to run or not to run gdb.
Breakpoint
Running through the program does not yield enough meaningful information. We need to halt the execution just before the printf line. Enter breakpoints, just like when working with a compiler. We will break into the main function and then advance step by step until the problem occurs again, then rerun and break, then execute commands one at a time just short of the segmentation fault.
To this end, we need the break command, which lets you specify breakpoints either against functions, your own or third-party loaded by external libraries or against specific lines of code in your sources - an example is on the way. Then, we will use info command to examine our breakpoints.
We will place the break point in the main() function. As a rule of thumb, it's always a good place to start.
break main

Now we run again. The execution halts when we reach main().

Step by step, oooh babe
Now that we have stopped at the entry to main, we will step through code line by line, using the next command. Luckily for us, there isn't that much code to walk through. After just two steps, we segfault. Good.

We will now rerun the code, break in the main(), do a single next that will lead us to printf, and then we will halt and examine the assembly code no less!

Disassembly
Indeed, at this stage, there's nothing else the code can tell us. We have exhausted our understanding of what happens in the code. Seemingly, there doesn't seem to be any great problem, or rather, we can't see it yet, supposedly.
So we will use the disassemble command, which will dump the assembly code. In a way, it's no different than what we did when using objdump against a binary in the kernel crash example. The big difference is, you have a full control of your execution here, so you don't need to understand everything, just limit your work to a small subset of code.
Just type disassemble inside gdb and this will dump the assembly instructions that your code uses. It will look like the screenshot below.

This is probably the most difficult part of the tutorial yet. Assembly code is not easy to digest and looks like Rain Man's afternoon fun. Let's try to understand what we see here, again in very simplistic terms.
On the left, we have memory addresses. The second column shows increments in the memory space from the starting address. The third column shows the mnemonic. The fourth column includes actual registers and values.
If you feel lost, consider reading the TL;DR section below, to get even more lost.
All right, there's a little arrow pointing at the memory address where our execution is right now. We are at offset 40054b, and we have have moved the value that is stored 8 bytes below the base pointer into the RAX register.One line before that, we moved the value 0 into the RBP-8 address. So now, we have the value 0 in the RAX register.
0x00000000400543 <+15> movq $0x0,-0x8(%rbp)
0x0000000040054b <+23> mov -0x8(%rbp),%rax
Our next instruction is the one that will cause the segmentation fault, as we have seen earlier while next-ing through the code.
0x0000000040054f <+27> mov (%rax),%edx
So we need to understand what's wrong here. Let's examine the EDX register, which is supposed to get this new value. We can do this by using the examine or x command. You can use all kinds of output formats, but that's not important right now.
x $edx

And we get a message that we cannot access memory at the specified address. This is the clue right there, problem solved. We tried fondling memory that is not to be fondled. As to why we breached our allocation and how we can know that, we will learn soon.
Not so simple example
Now, we do something more complex. We'll create a dynamic array called pointer, which also happens to be a pointer, there's a punny pun right there. We'll use the standard malloc subroutine for this. We will then loop, incrementing i values by 1 every iteration, then let pointer exceed its allowed memory space, AKA heap overflow. Understandable as a lab case, but let's see this happen in real life and how we can handle problems like these. Most importantly, we will learn additional gdb commands.
Here's the source:
#include <stdio.h>
#include <stdlib.h>
main()
{
int *pointer;
int i;
pointer = malloc(sizeof(int));
for (i = 0; 1; i++)
{
pointer[i]=i;
printf("pointer[%d] = %d\n", i, pointer[i]);
}
return(0);
}
Let's compile:
gcc -g seg.c -o seg
When we run it, we see something like this:
./seg
...
pointer[33785] = 33785
pointer[33786] = 33786
pointer[33787] = 33787
Segmentation fault
Now, before we hit gdb and assembly, let's try some normal debugging. Ley's say you want to try to solve the problem with one of the standard system admin and troubleshooting tools like strace. After having heard of strace on Dedoimedo, you know the tool's worth and you want to attempt the simple steps first. Indeed, strace works well in most cases. But here, it's of no use.
15715 write(1, "pointer[33784] = 33784\n", 23) = 23
15715 write(1, "pointer[33785] = 33785\n", 23) = 23
15715 write(1, "pointer[33786] = 33786\n", 23) = 23
15715 write(1, "pointer[33787] = 33787\n", 23) = 23
15715 --- SIGSEGV (Segmentation fault) @ 0 (0) ---
15715 +++ killed by SIGSEGV +++
Nothing useful there really. In fact, no classic tool will give you any indication what happens here. So we need a debugger, gdb in our case. Load the program.
gdb /tmp/seg
Breakpoint
Like before, we set a breakpoint. However, using main() is not going to be good for us, because the program will enter main() once and then loop, never going back to the set breakpoint. So we need something else. We need to break in a specific line of code.
To determine the best place, we could run and try to figure out where the problem occurs. We can also take a look at our code and make an educated guess. This should be somewhere in the for loop of course. So perhaps, the start of it?


Condition
All right, but this is not good enough. We will have a break point at every entry to our loop, and from the execution run, we see there are going to be some 30K + iterations. We cannot possibly manually type cont and hit Enter every time. So we need a condition, an if statement that will break only if a specific condition is met.
From our sample run, we see that the problem occurs when i reaches the value of 33787, so we'll place a conditional break some one or two loop iterations before that. Conditions are set per breakpoint. Notice the breakpoint number, after it is set, because we need that number to set a condition.
break 10
Breakpoint 1 at ...
And then:
condition 1 i == 33786

If you had multiple breakpoints and you wanted to set multiple conditions, then you would invoke the correct breakpoint number. All right, we're ready to roll, hit run and let the for loop churn for a while.

All right, now we walk through the code, step by step using the next command.

All right, we know the problem occurs after pointer[i]=i is set, when the i value is 33787. Which means, we will rerun the program and then stop just short of executing the pointer[i]=i line of code after a successful print of pointer[33787] = 33787.
Now, the next time we reach this point, we create the assembly dump.
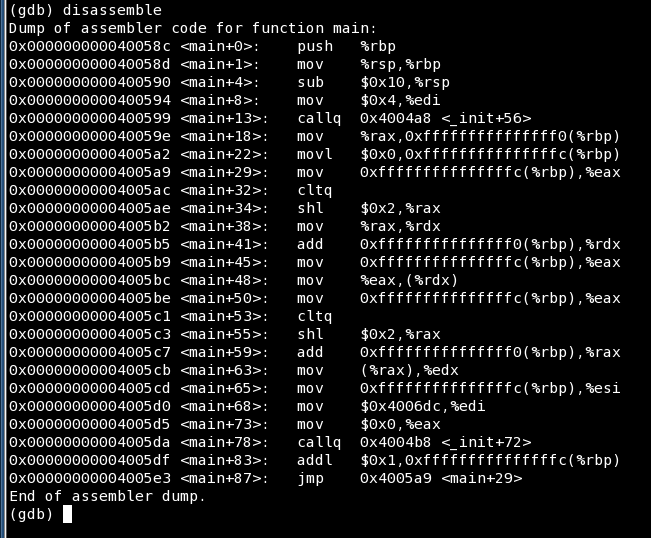
We know the problem occurs at offset 4005bc, where we mov %eax value into %rdx. This is similar to what we saw earlier. But we need to understand what happens before that, one or two instructions back.
Stepping through assembly dump
To this end, we will use the stepi command, which can walk the assembly dump, line by line. It's like next in a way, but you can control individual registers, so to speak.
Take a look at the dump. The last line in the dump is the jump (jmp) instruction back to offset <main+29>, which brings us to mov 0xfffffffffffffffc(%rbp), %eax. This is effectively our for loop. Now, when we hit stepi, we will execute line 4005ac. I omitted the line that reads cltq, because it merely extends the 2-byte EAX into a 4-byte value, that's because we're on a 64-bit system.

Now, we have several lines where the i value is incremented and whatnot. But the crucial line is just one short of the segmentation fault. We need to understand what's inside those registers or if we can access them at all.

And turns out we can't. It's like we had earlier. But why? How can we know that this address is off limits? How do we know that?
proc mappings
In Linux, you can view the memory maps of any process through /proc/<pid>/maps. It is important to understand what a sample output provides before we can proceed. I'm not going to elaborate too much, but basically:

The first line is the code (or text), the actual binary instructions. The second line shows data, which stores all initialized global variables. The third section is the heap, which is used for dynamic allocations, like malloc. Sometimes, it also includes the .bss segment, which stores statically linked variables and uninitialized global variables. When the .bss segment is small, it can reside inside the data segment.
After that, you get shared libraries, and the first one is the dynamic linker itself. Finally, you get the stack. The two last lines are the Linux gating mechanisms for fast system calls, which replaces the int 0x80 system call that was used in olden days. As you may notice, there are still more memory addresses above the last line, reserved by the kernel.
So here, at a glance, you can examine how your process resides in the memory. When a program is executed through gdb, you can view its memory allocations using the info proc mappings command.
info proc mappings

Three lines, code, data, heap. And for heap, we can see that the end address is 0x522000. And we can't be using that, so we get our lovely segmentation fault. Back to C code, we will need to figure out what we did wrong, whether we molested our integer, tried an illegal allocation or double freeing or whatever.
Now, if you really wanna go Rain Man on this, you can start counting bytes. In general, we use a single page for code, because our executable is small. We use a single page for data. And then, there's some heap space, a total of 0x21000, which is 132KB or more specifically 135168 bytes.
On the other hand, we ran through 33788 iterations of the for loop, each 4 bytes in size, as we're on a 64-bit system. Not 33787 as you may assume from the print output in our program run, but one more, because we started counting i at value 0.
So we get 135152 bytes, which is 16 bytes less that our heap. So you may ask, where did the extra 16 bytes go? Well, we can use the examine command again and check more accurately what happens at the start address.

We print eight 4-byte hexadecimal values. The first 16 bytes are the heap header and the count starts at address 0x501010. So we're all good here, and we know why we got our nasty segmentation fault. We can examine our source code and try to figure out what we did wrong. Two examples, two problems solved.
Now, we will talk some more about using gdb in general, including collecting application cores and analyzing them, attaching to running processes, more tips on popular gdb commands, and we'll see yet another example, which shows when gdb is not really useful and yet the assembly dump will tell us all we need, even if we do not have sources.
General advice & more stuff
Analyzing application cores
Similar to kernel crashes, application crashes can create cores that you can analyze later on. There are a few things that you need to make sure are properly set in the system before you can analyze cores.
Enable application cores
You will have to make sure that you can create cores. This is governed via sysctl, but you can also make changes on the fly. Depending on your shell, you will use either the limit or ulimit builtins.
ulimit -c unlimited
And for TCSH:
limit coredumpsize unlimited
Core format
By default, the core will be dumped in the current directory where the binary was executed. But the core name might not be useful of meaningful. So you can change its format, which is governed by the core_pattern setting under /proc. For example:
echo "/tmp/core-%p-%u" > /proc/sys/kernel/core_pattern
This will dump a core under /tmp, with the PID and UID suffixed. There are many other available options. You can also set this option permanently via sysctl.conf. For more reading, perhaps you want to consult this cyberciti article and this Novell cool solution.

Invoke gdb against core file
Next, your application will crash and create a core. Then, use gdb as follows:
gdb <binary> <core>

The important thing is that gdb successfully read and loaded the symbols. We can now proceed with the analysis, like before. Some functions will not be available to us, as the core is not a running application, but we will still be able to figure out what went wrong.
Attach to a running process
Similarly, you may want to attach gdb to a running process. As it happens, you may have a problem right now, so you cannot restart the program and try to reproduce the issue at leisure. This may not be the most effective way of debugging problems, but it could give you additional information that may not be available otherwise.
The simplest way to demonstrate this is by altering our example with an extra sleep somewhere. Then, while the program is running, find its PID and attach to it.
gdb -p <process id>

This example also shows the fact the third-party libraries are stripped, so you get function names, but you don't know the exact lines of code or the variables. Moreover, using the backtrace (bt) command, we see we're currently sleeping.
Other useful commands
Let's list down a few other commands you may want to try and use.
show lets you show contents, as simple as that. set lets you configure variables. For example, you may want to see the initial arguments your program started with and then change them. In our heap overflow example, we could try altering the value of i to see if that affects the program.

The syntax for setting variables is quite simple. set i=4 would do. You can also set registers, but don't do this if you don't know what you're doing. list lets you dump your code. You can list individual lines, specific functions or entire code. By default, you get ten lines printed, sort of like tail.
Another thing you may want to do is inspect stack frames in detail. We're already familiar with the info command, so what we need now is to invoke it against specific frames, as listed in the backtrace (bt) command. In our heap overflow example, there's only a single frame.
We break in main, run, display the backtrace and then check info frame 0, as shown in the screenshot below. You get a wealth of information, including the instruction pointer (RIP), the saved instruction pointer from a previous frame, the address and the list of arguments, the address and the list of local variables, the previous stack pointer, and saved registers.

I mentioned backtrace (bt) earlier, and indeed, it is a most valuable command and best used when you don't know what your program is doing. External commands can be executed using the shell command. For instance, showing the /proc/PID/maps can also be done by using the shell cat /proc/PID/maps instead of info proc mappings as we did before. If for some reason you cannot use either, then you might want to resort to readelf to try to decipher the binary. Like we used next and stepi, you can use nexti and step. Let's not forget finish, jump, until, and call. whatis lets you examine variables.
And that's enough for this section, I guess.
When to use or not use gdb?
All right, gdb is useful when you have reproducible problems and your binaries have been compiled with symbols. You can also try using gdb against third-party functions, but this won't guarantee much success.
For instance, we know we're using printf() in our code. So maybe we need to break there? Well, gdb will informs us that the function is not defined and will create a breakpoint pending on future shared library load. Not a bad idea, but do notice that we don't see any function names for libc.so.6, because we don't have symbols, and for that matter, we might not even have sources. Without either, it will not be easy figuring out what went wrong.
(gdb) break printf
Function "printf" not defined.
Make breakpoint pending on future shared library load? (y or [n]) y
Breakpoint 1 (printf) pending.
(gdb) run
Starting program: /tmp/segfaults/seg
Breakpoint 2 at 0x2aaaaac113f0
Pending breakpoint "printf" resolved
Breakpoint 2, 0x00002aaaaac113f0 in printf () from /lib64/libc.so.6
Finally, using gdb for sporadic, random problems that are not easily reproduced or those that might stem from hardware problems is a hard, grueling task that will yield few results. Even the trivial examples are not so trivial, so imagine what happens on a real production system, with binaries compiled from sources with thousands of lines of code. Still, you get a taste of the goodness, and you're hooked now.
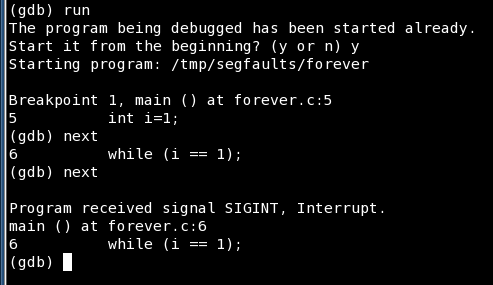
Lastly, let's see an example where gdb is both the worst and best tool for analysis. We'll create an infinite loop program, nothing sinister, just a bit of while true thingie. This kind of program will loop forever, churning CPU.
If you try strace, you see this - useless:

If you try gdb, it works, we can break in main just fine, but after several next commands, even gdb seems to hang. In this case, you will have to interrupt the execution to get back to your code. Now, with symbols, it's trivial seeing where the problem lies. But let's assume that we have nothing; we only know where the problem manifests.
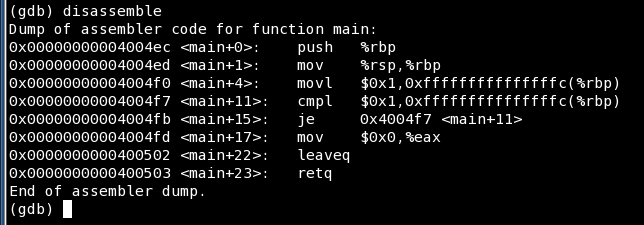
All right, enter disassembly once again. The important thing is that our program revolves around two instructions. You have the comparison (cmpl) and the jump (je). We're in a tight loop. Naughty. But even if you don't have the sources, even if the program has no symbols and you don't know what it's doing, you can still figure out what's wrong.
TL;DR - Read only if you're bored
Here's a bit more about what we saw in the disassemble section. It may help you understand a little better how things work.
Let's examine the top three lines.
0x00000000400534 <+0> push %rbp
0x00000000400535 <+1> mov %rsp,%rbp
0x00000000400538 <+4> sub $0x20,%rsp
These three lines are called the Function Prologue, and it's automatically added by the GCC compiler on the standard x86 (32-bit) and x86_64 (64-bit) architectures. I'm not sure how things behave on other processors.
The Function Prologue has one function [sic] - to preserve the value of the base pointer of the previous frame on the stack, or in other words, the calling function's stack frame. On the 32-bit architecture, the EBP register is used for this purpose, on the 64-bit architecture, the RBP register.
So the first instructions pushes (decrements) the stack pointer. Note: the stack grows downwards, so to speak, but this is part of those boring prerequisites we talked about earlier. Then, the stack pointer value is copied into the base pointer register. The third instruction allocates space of 20 bytes for function's local variables. sub $0x20,%rsp can also be translated as %rsp-20. The actual value will depend on the function's declaration.
Similarly, at the end of the assembly dump, there's the Function Epilogue, which does exactly the same like the Prologue, in reverse. The epilogue consists of the leave and ret instructions. In our example, leaveq, retq.
In between, we have all kinds of instructions that depend entirely on how the function is written and what it does. We've seen enough earlier, so no need to elaborate more.
To more know about stack frames, you use the backtrace (bt) command and then info. In our two examples, the trace is simple, with just one frame each, but some programs may have 10-15 frames, etc. This is especially useful if you don't know what the binary is supposed to be doing.

Some more reading
You can read more about AT&T Assembly in this quick 'n' dirty guide.
You can also read more about the x86 (and x86_64) assembly language on Wikipedia.
And let's not forget Call stack.
Conclusion
This was ultra-geeky, I admit, but I think you liked it, if you got this far. Working with gdb is not a simple deal, but the tool is extremely versatile and powerful. You will need a lot of time mastering its commands and abilities to the fullest, best done with real problems that truly emphasize what you're doing. For starters, grab some bad C code and start practicing.
We learned how to work our way through the code, with break points and conditions, next and stepi commands, assembly dumps, info on various important elements, and whatnot. Alongside the vast array of other powerful tools and admin hacks that I've taught you before, your Linux pimpage ought to climb majestically. Stay sweet.
Many thanks to Mr. Avi for some of the tips and ideas!
Cheers.