Updated: June 20, 2012
Once article numbers start to run high, people tend to start paying less attention to the content. However, by no means does that make this article any less useful or interesting. I happen to have a fresh new bunch of tips and tricks that ought to increase your Linux street credit.
In the first two parts, we focused on system administration mostly. The third part focused on system internals. This fourth chapter will elaborate on compilation and fiddling with Linux binaries, specifically the ELF format. Again, not everyone's lunch or dinner, but some of you may appreciate the extra geekiness I devoted to making your lives easier. So please follow me.

1. Learn more about the file - no strings attached
Say you have a binary of some sort - a utility, a shared object, a kernel module, maybe even an entire kernel. Now, using file will give some very basic information on what kind of object you're dealing with. But there's more. Strings. Now, the subtitle makes a lot of punny sense, hihihihihihi.
Strings is a very useful command that can pull out all printable characters out of binary files. This can be quite useful if you need to know the would-be meta data, like compiler versions, compilation options, author, etc. For example, here's what it looks like for a kernel vmlinuz file. Some of you may actually recognize some of the print messages there.

2. Debugging symbols
Now, say you wish to debug your faulty application, but for some reason all of the functions in the backtrace come out with ?? marks. The simple reason is that you may not have debug symbols installed. But how would you know?
Well, apart from checking the installed database of RPM of DEB files, you may want to query the files directly. Again, we will use the file command, and then delve deeper into the system. Here's an example:

What we see here is that we have a 32-bit Little Endian shared object for the Intel architecture, stripped of symbols. That's what the last word tell us. This means the binary was compiled without symbols or they have been removed afterward to conserve space and improve performance. We discussed symbols in the Kernel Crash book, too.
So how do you go about having or not having debug symbols? Another highly useful tool that should let you get binary symbols is nm. This tool is specifically designed to get symbols from various sections in the executable file format that is typical on Linux.
For instance, -b flag lets you get symbols for uninitialized global variables in the data section, also known as bss. -C lets you query common symbols, or rather uninitialized data. In our example, there are none available, because our shared library is stripped.

However, if you query with -D flag, you will get symbols in the initialized data section.

For most people, this information is completely useless. But for senior system admins and software developers, knowing exactly the mapping of code in a binary and translation of memory addresses to function names is essential.
Playing with symbols - objdump, objcopy, readelf
We can add and remove them, as we please, after the compilation. To that end, we will use several handy utilities, including objcopy and readelf. The first allows manipulating object files. The second lets you read data from binary files in a structured human readable format.
We will begin with readelf. The simplest way is to dump everything. This can be done using -a flag, but beware the torrents of information, which probably won't mean much to anyone but developers and hackers. Still good to know and impress girls.
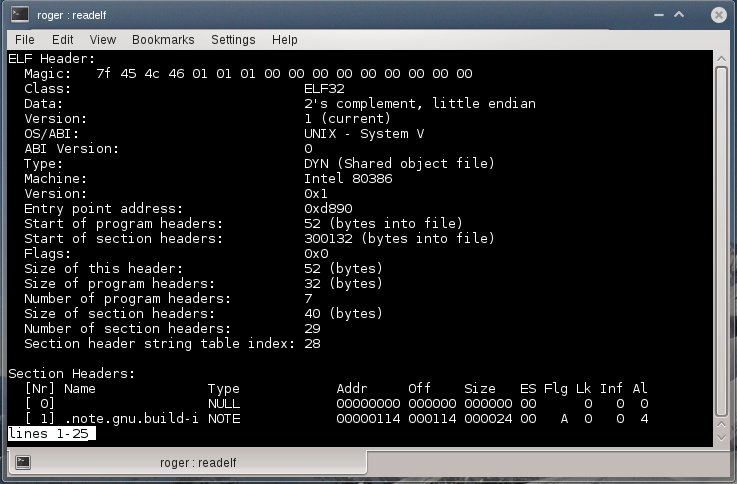
Another useful flag is --debug-dump=info. You might be interested in debuginfo only. Here, specifically, we compile our test tool with debug symbols, and then display the info. Please note that we have a lot of information here:

Now, objcopy can manipulate files so that above information is shown, not shown or used elsewhere. For instance, you might want to compile a binary with debug symbols for testing purposes, but distribute a stripped version to your customers. Let's see a few practical use cases.
To remove debug info from the original binary:
objcopy --strip-debug foo
This will result in a stripped binary, just like we saw earlier. But then, you might not want to toss away those symbols permanently. To that end, you can extract debug info and keep it into separate file:
objcopy --only-keep-debug foo foo.dbg
And then, you can link debug info back to the stripped binary when you need it:
objcopy --add-gnu-debuglink=foo.dbg foo
On the far end of the spectrum, we get objdump, another handy utility. Again, we used the program before, when playing with kernel crashes, so we are no strangers to its power and functionality. Similar to readelf, objdump let us obtain information from object files. For example, you may be interested in the comment section of your binary:
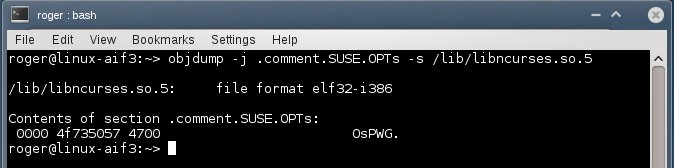
Or you may want everything:

Combined example
Now, let's see this in practice. First, we compile our code with -g flag. The binary weighs some 18299 bytes. Then, we strip debug information using objcopy. The resulting binary is now much smaller, at 13042 bytes. And readelf shows nothing, unlike before.

3. Compilation optimization tips
When compiling your code, there are a billion flags you can use to make you code more efficient, leaner, more compact, easier to debug, or something else entirely. What I want to focus on here is the optimization during the compilation. GCC, which can be considered a de-facto compiler on pretty much any Linux, has the ability to optimize your code. Quoting from the original website:
Without any optimization option, the compiler's goal is to reduce the cost of compilation and to make debugging produce the expected results. Statements are independent; if you stop the program with a breakpoint, you can then assign a new value to any variable or change the program counter to any other statement in the function and get exactly the results you would expect from the source code. Turning on optimization flags makes the compiler attempt to improve the performance and/or code size at the expense of compilation time and possibly the ability to debug the program.
In other words, the compiler can perform optimizations based on the knowledge it has of the program. This is done by intermixing your C language with Assembly in numerous ways. For example, simple arithmetic procedures of constant values can be skipped altogether and the final results returned, saving time.
Optimizations can affect binary file size and its speed or both. At the same time, it will be much harder to debug, because some of the instructions may be omitted. Moreover, the compilation time will probably be longer. Overall, -O2 levels offers a good compromise between user's ability to debug, size and performance. It is also possible to recompile code with -O0 level for debugging purposes only and ship to customers with the lean image.
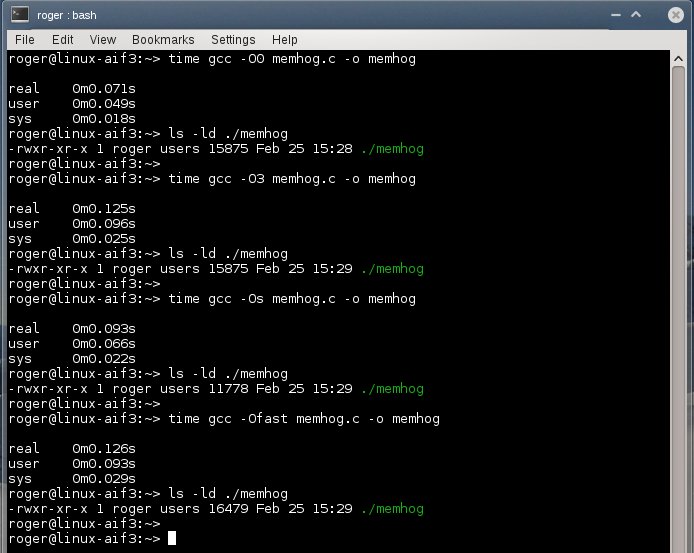
Here's another interesting article on optimizations.
4. LDD (List Dynamic Dependencies)
When you try to run your applications, they may sometimes refuse to start, complaining about missing libraries. This can happen for several reasons, including permissions, badly configured path or an actual missing library. To be to know exactly what's going on, there's a neat little utility called LDD. It allows you to print shared library dependencies for your binaries. You should use it.

LD_PRELOAD and LD_LIBRARY_PATH
As I've mentioned just moments earlier, the system path can impact the successful startup of applications. For example, you may have several libraries under /opt, but /opt is not defined in the search path, which may only include /lib and /lib64, for instance. When you try to fire up your program, it will fail, not having found the libraries, even though they are physically there. You can work around this issue without copying files around by initializing environment variables that will tell the system where to look.
The word system sounds almighty here, so perhaps a short introduction in how things work might be in order. In Linux, there's the super-tool called dynamic linker/loader, which does the task of finding and loading libraries for programs to run. ld.so is a smart and efficient tool, so it does not perform a full-system search every time it needs to fire up a binary. Instead, it has its own mini-database, stored under /etc/ld.so.cache, which contains a compiled list of search libraries and an ordered list of candidate libraries. It's somewhat similar to the locate program.
This list is updated by running ldconfig, which most Linux systems execute either during startup or shutdown, but it can be manually run whenever the /etc/ld.so.conf file, which contains the list of search libraries, is updated. This also happens after installations of software.
If the linker cannot find libraries, the loading of the program will fail. And you can use LDD to see exactly what gives. Then, you can use the environment variables LD_PRELOAD and LD_LIBRARY_PATH to force loading of libraries outside the search path.
There is some difference between the two. LD_PRELOAD will force loading of these libraries before any other. LD_LIBRARY_PATH is similar to standard PATH. There are many other variables you can change, but that's what the man page is for.
One last hack that you might be interested in is rpath. It allows hard-coding runtime search paths directly into the executable, which might be necessary if you're using several versions of the same shared library, for instance.
Recursive implementation
LDD displays only unique values. But you might be interested in a recursive implementation. To that end, you might want to check the Recursive LDD tool, available for download at Sourceforge.net. It's a simple Perl script, with some nice tweaks and options. Quite useful for debugging software problems.

5. Some more gdb tips
We learned a lot about gdb. Now, let's learn some more. Specifically, I want to talk to you about the Text User Interface (TUI) functionality. What you want to do is fire up the venerable debugger with -tui option. Then, you will have a sort of a split-screen view of both your code and the gdb prompt, allowing you to debug with higher visual clarity. All the usual tricks still apply.

You might also be interested in this article.
6. Other tips
The one last extra tip is about translating addresses into file names and line numbers. addr2line translates addresses into file names and line numbers. Given an address in an executable or an offset in a section of a relocatable object, it uses the debugging information to figure out which file name and line number are associated with it.
addr2line <addr> -e <executable>
A geeky example; say you have a misbehaving program. And then you run it under a debugger and get a backtrace. Now, let's assume we have a problematic frame:
# C [libz.so.1+0xa910] gzdirect+0x28
All right, so we translate (-e tells us the name of the object). Works both ways. You can translate from offsets to functions and line numbers and vice versa. Again, this can be quite handy for debugging, but you must be familiar with the application and its source.
addr2line 0xa910 -e libz.so.1
/tmp/zlib/zlib-1.2.5/gzread.c:614
addr2line -f -e libz.so.1.2.5 0xa910
gzdirect ? function name
/tmp/zlib/zlib-1.2.5/gzread.c:614
More reading
You might also want to check these:
Linux super-duper admin tools: strace and lsof
Linux system debugging super tutorial
Highly useful Linux commands & configurations
Conclusion
I assume this article is only for the brave, bold and beautiful. It's definitely not something the absolute majority of you will ever want, need, see, try, require, or anything of that sort. But then, if you're after impressing girls, there's no better way of doing it.
Along that noble cause, this tutorial also presents some handy tips for software development and debugging, which, combined with a deep understanding of system internals and wise use of tools like strace, lsof, gdb, and others, can provide an awesome wealth of useful information. We learned how to read and extract information from files, how to work with symbols, how to read the binary format, compilation tips, dynamic dependencies, and several other tweaks and hacks. That should keep you busy for a week or there until you figure out everything. Meanwhile, do send me any ideas you may have on similar topics, if you feel there ought to be a tutorial out there. And see you around.
Cheers.