Updated: November 11, 2013
This is a hot topic. A very hot topic. What do you do if you have several Word files, either saved as .doc or .docx, which no longer open? You do not have backups, which you should, or perhaps the backups are corrupt, too? How do you gain back the long page after page of valuable text? This article will help you with this unpleasant task.
I will show you two somewhat unusual methods of recovering contents of your files. The success is not guaranteed, and your final formatting might not be preserved. But you will definitely be able to save your text, which ought to be the most important part. Best of all, Linux to the rescue! We will use Linux to do some of the recovery work. Follow me.
Expectations
Let's align expectations upfront. File recovery is a tedious guesswork. Sometimes, it will work, sometimes it won't. You can make a best effort to retrieve the data, but it may really not be there. If data has been overwritten with nonsense, you will not be able to reassemble what was lost, ever. For instance, if a certain file has zeros accidentally written in its middle, the bytes that represent actual content will be gone.
Moreover, what I am showing you here is an incomplete workaround. There's no exact science, and most likely, no two cases will ever be quite the same. On top of that, some basic expertise is needed, including the ability to use regular expressions to some extent. The Linux requirement can also make it more difficult for most Windows users. However, between the tough choice of losing everything and hopefully recovering 50-70% of your missing stuff, you should definitely give this tutorial a try. It's free, it's non-destructive, so you can always try expensive professional services later on. There's always time to give someone your money.
How to recover docx files
Here's a sample file, as it ought to look in Word.

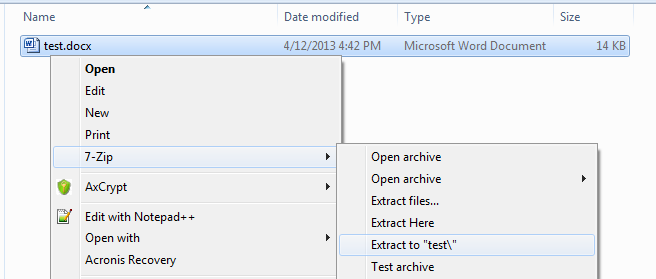
Now, for some reason, it no longer opens. Never mind. Let's fix it. Believe it or not, DOCX files are actually archives - ZIP archives if you will. So while they appear to be a single file, they are actually full of goodies. Extract your file using something like 7-Zip.
Change directory into the extracted folder. You will find several sub-folders inside, containing various meta data that identify your document. Always wondered why even an empty Word file weighs about 20-25KB? The answer is, the file object has tons of invisible fields that identify it, and these are spread about in a variety of files.

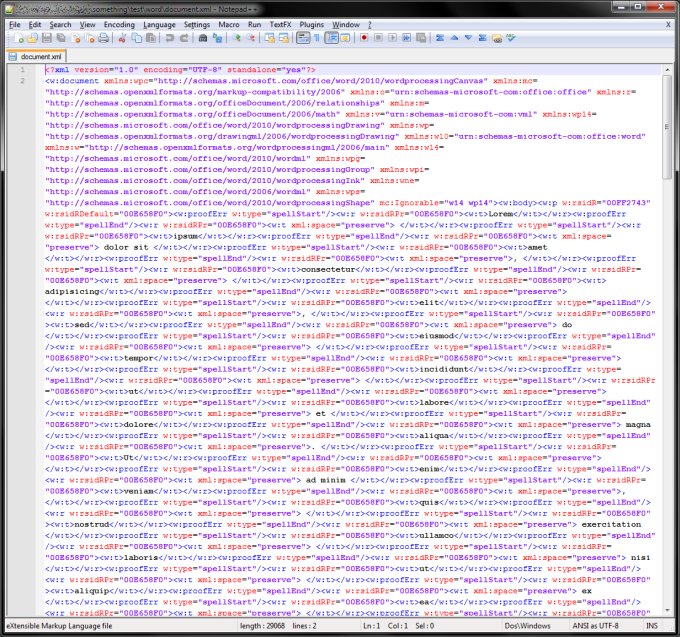
Open the document.xml file and take a look at it. It's your file, with tons of other stuff, which you don't need. So we will need to cleanup things a little.
Install Notepad++ or just use it, in case you have it installed, as you should really. It's one of my most recommended productivity tools for Windows people, and I even use it inside Linux. There's really little that this awesome text editor cannot do. So we are going to use it to cleanup our XML files of all the meta data. Open the extracted document.xml file in it. Then, go to:
Menu > TextFX > TextFX Convert > Strip HTML tags table tabs
Menu > TextFX > TextFX Convert > Strip HTML tags table nontabs
And you will have your text! But you will lose paragraphs. Still, it's so much better than nothing. Anyhow, here's an example. Let's clean up the horrible mess in our XML file:

And it becomes this lovely thing:
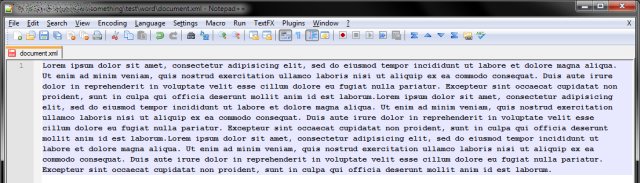
Regular expressions
Well, we did it an easy way. Now, we will do it the hard way. Note: We will have two sections here. One, an introduction to how one might want to slowly progress through their XML data and parse needed or unneeded contents out of certain data blocks. Then, we will have a quick way of doing it. The quick hard way, that is.
So, let's begin with a simple, introductory step. In addition to what we did earlier using TextFX, we can also use regular expressions. We will do it in Notepad++ first. For starters, we need to split the document into multiple lines so we can more easily manipulate it. In the Find & Replace dialog, use <w expression for find and \n<w for replace. Do not forget to mark Regular expression in the Search Mode. So what do we have here? We're looking for all opening brackets of XML tags and adding a new line before them, hence the newline character.

The document.xml file now looks as follows:

So now we want to remove all XML tags, but keep the text within brackets. We will need the following expression in the find field: <.*>(.[^>]*)<\/.*> and the following expression in the replace field: \1. Again, what we have here is, a regex that will strip meta tags and return only the first selection found, hence that \1 expression.
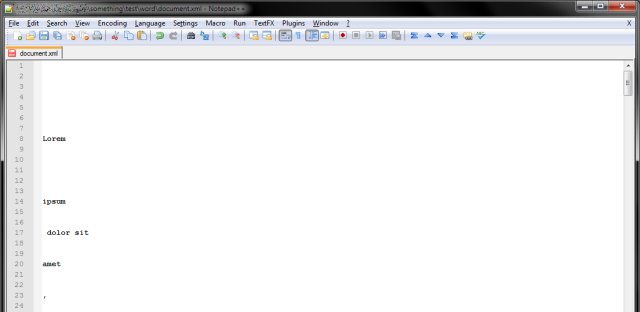
Once we complete, this, we will still be left with some lines containing meta data. It will look something the following block of text:
<w:r w:rsidRPr="00E658F0">
Lorem
<w:proofErr w:type="spellEnd"/>
<w:r w:rsidRPr="00E658F0">
<w:proofErr w:type="spellStart"/>
<w:r w:rsidRPr="00E658F0">
ipsum
<w:proofErr w:type="spellEnd"/>
<w:r w:rsidRPr="00E658F0">
dolor sit
<w:proofErr w:type="spellStart"/>
<w:r w:rsidRPr="00E658F0">
amet
<w:proofErr w:type="spellEnd"/>
<w:r w:rsidRPr="00E658F0">
,
<w:proofErr w:type="spellStart"/>
<w:r w:rsidRPr="00E658F0">
We will now remove those too. For find: <.*>. For replace: nothing.
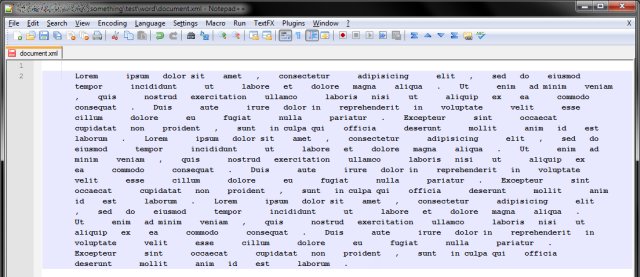
Finally, we will reassemble the lines back. So we will replace \n with the space character. I'd recommend the space character, in case some of the original spaces were lost. You can always remove double spacing later on.
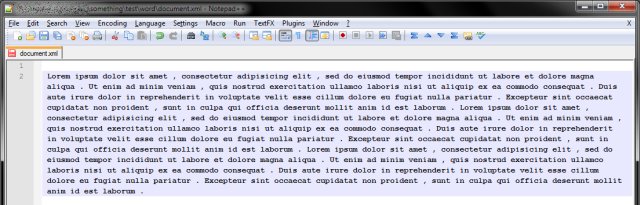
And then, trim the extra spaces: Find: [\s]+. Replace: space - an actual space. And we're done. Here's the final text output following our regex saga. You will notice spaces preceding the comma and period character, but that can be sorted out too.
Quick way!
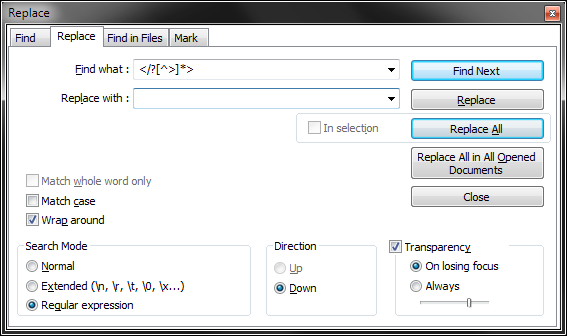
Now, if you are comfortable with the section we just went through, you can start practicing much more aggressive, faster regular expressions that will sanitize junk out of your documents. Here it is. Find: </?[^>]*>. Replace: space. And that's it. Try it.
Same thing, in Linux
We will do the same thing in Linux:
unzip file.docx -d file-dir
Then, change directory into the word sub-directory. And now run a series of lovely sed replacements, using regular expressions. This is not going to be easy, but it does what you expect:
cat document.xml | sed 's/<w/\n<w/g' |\
sed 's/<.*>(.[^>]*)<\/.*>/$1/g' |\
sed 's/<.*>//g' |\
sed 's/^$/ /g' |\
sed 's/[\s]+/ /g'
And here's the much simpler way:
cat document.xml | sed 's/<\/?[^>]*>/ /g'
You can output the result to some text file and work from there. If you are comfortable, you can use the inline replacement straight away. Now, I'm not a regex expert, by far. Totally not. My expression is probably not the most optimal, so if YOU have any neat suggestions, this is your opportunity to shine. Perhaps you can present a more beautiful and elegant solution. I'm sure you can.
Word of caution!
Playing with XML and regular expression is rather risky. You might melt your brain. That said, you might be interested in testing and exploring various XML parsers, which could come handy one day. Some of the items that come to mind:
How to recover doc files
DOC files are binary files. Which means you cannot use the previous method of unpacking the archive and playing with the XML. To this end, you need a tool that can read the contents of binary files. And here we want Linux in earnest.
Strings to the rescue!
Strings is a command that strips text strings out of binary files. It is mostly useful for serious debugging and hacking, when you are trying to figure out how a certain file was compiled and whatnot. But it will do the same thing here.
strings file.doc
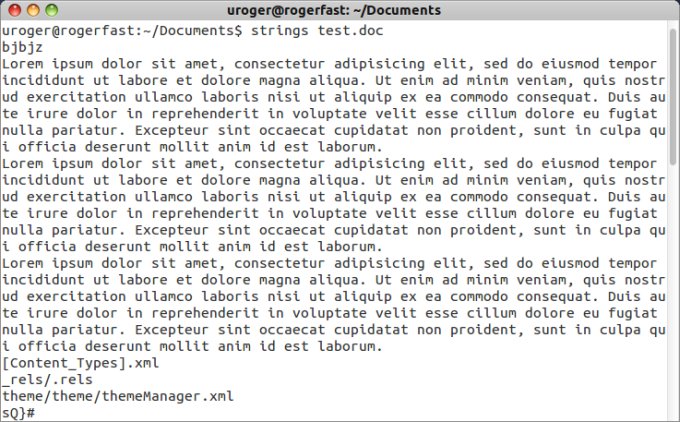
This is your best option, because strings will preserve paragraph breaks, so your post-catastrophe homework will be much reduced. This is an extremely useful command, and you should remember when and how to use it, especially when manipulating binary files that might contain human-readable content.
Header fixes
This is another interesting one, similar to what we did with broken media files in VLC. We also did a similar recovery on JPEG images. This time though, we will not be doing manual fixes to file bytes. We will do that in a separate tutorial. I promise.
I will be spending the coming months breaking and corrupting Word files in all sorts of ways, to see if I can find anything that can be of generic use for a wide population of my readers and their friends and family. Be patient, the tutorial shall yet arrive, from out of fire and smoke of despair. Or something like that.
More reading
Notepad++ plugin management
Recommended Linux productivity software
Recommended Windows productivity software
New cool list of Windows must-have programs
New cool list of Linux must-have programs
Best Linux software for 2012 and beyond
Conclusion
There you go. This is a fairly long and convoluted tutorial, but I think it has everything you can possibly want or need for text manipulation, with XML and binary files. The guide offers practical solutions for recovering contents out of both DOCX and DOC files, on both Windows and Linux. It teaches how to extract archives, how to sanitize text from XML files, how to use advanced features in Notepad++ and regular expressions, the use of the strings tool in Linux, plus there's a wealth of other resources. All free, not bad, I dare say.
Hopefully, this article does help you somewhat restore hope to your data recovery saga. You will never have a silver bullet solution to your mangled, corrupt files, but at least now, you have several useful, practical and unique ways of trying to glean valuable data from your documents. We have learned both GUI and command line usage, two different operating systems, several tools, several methods, so it's dandy. And the header manipulation coming soon. Stay tight.
Cheers.