Updated: March 30, 2020
Recently, finding really cool, new, unique Linux software has become a difficult task. A chore. And by recently, I actually meant these past four or five years, even since the slow decline of enthusiasm and innovation in the desktop space started. After all, there's a limit to how much good stuff can exist in a finite volume of intellect, but let's not forget the wrong shift of focus to mobile and the shattering of the year-of-the-Linux dream.
This makes my test of a four-year-old piece of software named OCRFeeder valid, I think. For two reasons. If it's good, it's good. Second, I've always been interested in the progress of optical character recognition, and whether our tools (read AI) can do a reasonable job here. I wrote about this in detail a while back, and then reviewed YAGF in 2015. Now, let's have a look at OCRFeeder and what it can do. After me, brave Linux warriors.
Words don't come easy to jpg
I installed the program. There's quite a few libraries that you need to grab. In Ubuntu 18.04, the list ran across quite a few lines. You get the Tesseract OCR engine as the default kit for this program.
The following additional packages will be installed:
blt gir1.2-goocanvas-2.0 gir1.2-gtkspell3-3.0 libgoocanvas-2.0-9 libgoocanvas-2.0-common
libgtkspell3-3-0 liblept5 libtesseract4 libyelp0 python-bs4 python-chardet python-enchant
python-html5lib python-lxml python-numpy python-olefile python-pil python-renderpm python-reportlab
python-reportlab-accel python-sane python-tk python-webencodings tesseract-ocr tesseract-ocr-eng
tesseract-ocr-osd tk8.6-blt2.5 unpaper yelp yelp-xsl
Suggested packages:
blt-demo python-gobject python-wxgtk3.0 python-genshi python-lxml-dbg python-lxml-doc gfortran
python-dev python-nose python-numpy-dbg python-numpy-doc python-pil-doc python-pil-dbg
python-renderpm-dbg python-egenix-mxtexttools python-reportlab-doc python-sane-dbg tix
python-tk-dbg
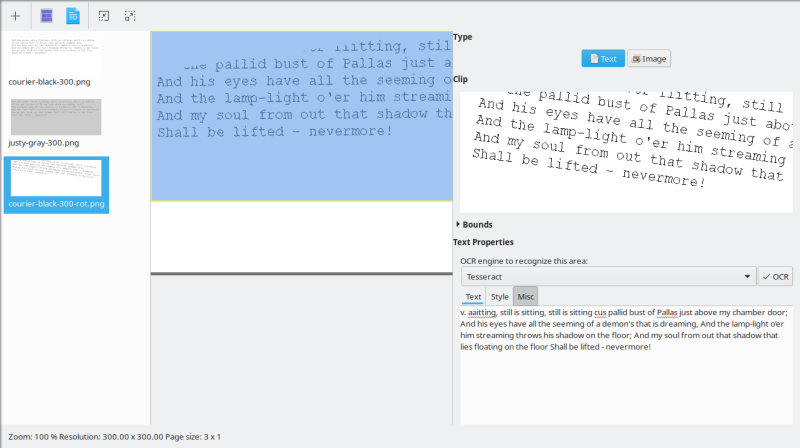
Launched it. The interface is a bit utilitarian. You first need to load one or more images, which you will then use to feed your OCR engine, and hopefully, it will have produced reasonable-accuracy text on the other end. Once you're done with this, you can then export the text to LibreOffice.

OCR engines
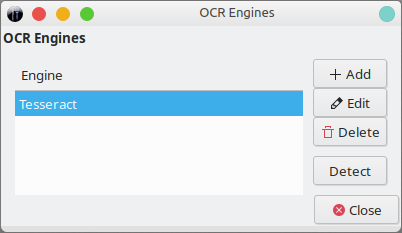
As I mentioned, By default, OCRFeeder will use Tesseract, but you can add any other engine you like. Indeed, I tried CuneiForm, GOCR and Ocrad, and the program correctly detected and loaded all of them. Very neat. This gives you the ability to try your documents in multiple ways, as you may have more luck with some of these engines.
sudo apt-get install cuneiform gocr ocrad
Image-to-text conversion
Now, the crucial part. I did struggle a little here. I let the program auto-detect text (recognize all pages) in all the available images, and I got some weird color-marked output. This thing took about three minutes to complete for the three loaded PNG files, and during that time, OCRFeeder CPU utilization was about 17%, and Tesseract was using about 4-5%. So times can definitely be shortened if the application does a better job of using all the processor cores. Then, the weird output. I wasn't quite sure what to do. Odd. It seemed like I wasn't making any progress at all.

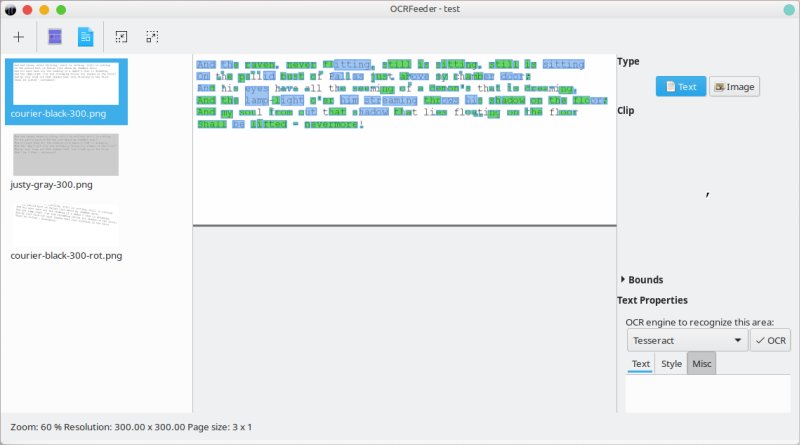
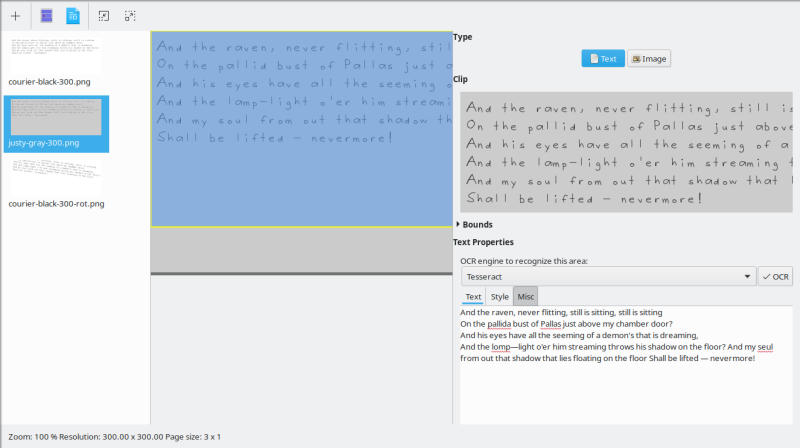
Then, I realized I could use the mouse to drag & select parts of displayed images, and then, a separate pane would open, where I could choose the desired OCR engine, and run the actual conversion. Visual glitches aside, this worked reasonably well, and it took only a few seconds to process each image.
Without any training or changes to defaults, the variation of results among the four available engines was huge. Tesseract displayed the best - and only acceptable conversion. The rest just weren't good enough to consider using at all. I'm not sure why, just the way it is.
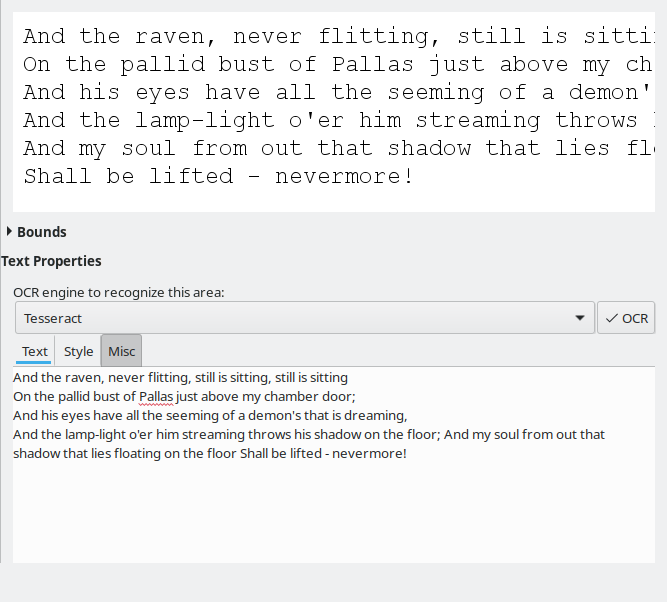
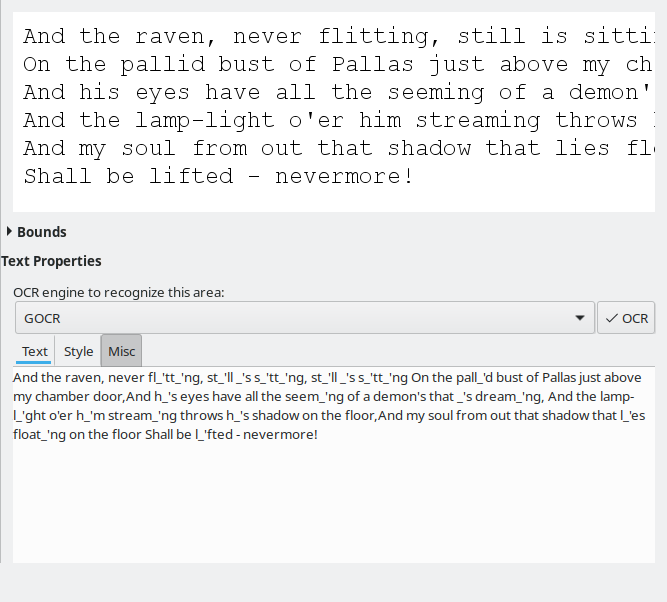
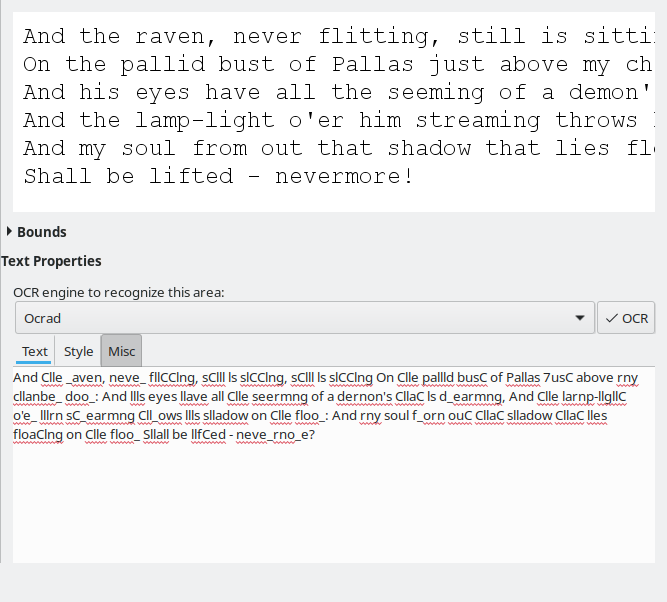
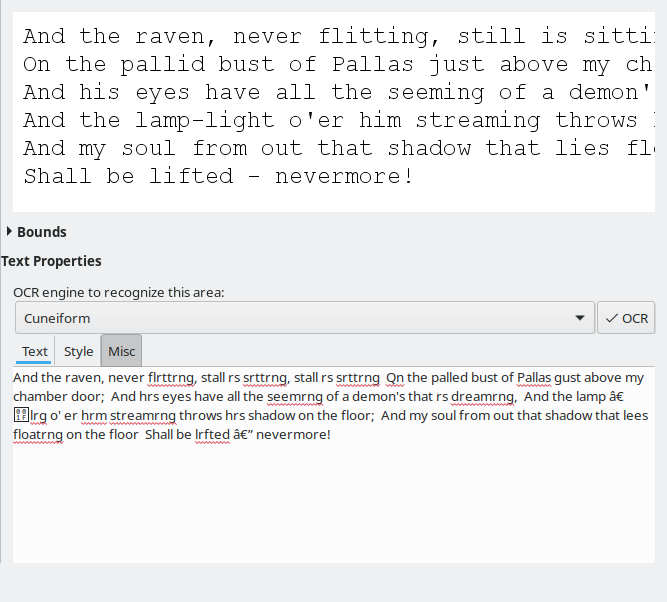
I also noticed better results with the gray-background image. In the past, Tesseract struggled, so whatever improvements had gone into this engine, they are most welcome. But then, this is not strictly an OCRFeeder thing, and you can run Tesseract on your own, from the command line, if you want.
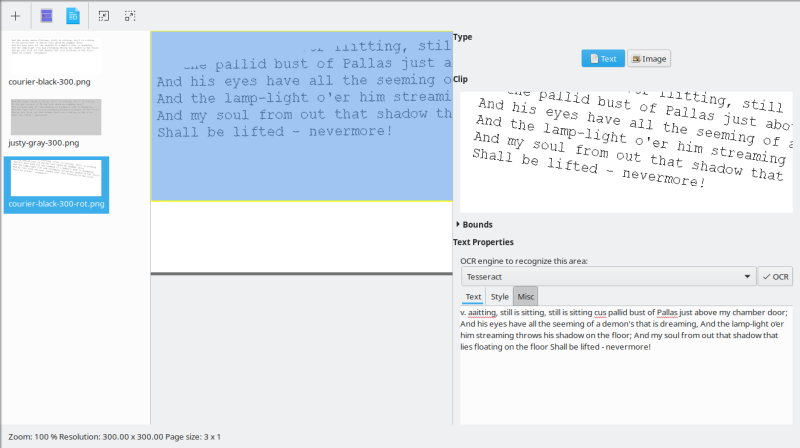
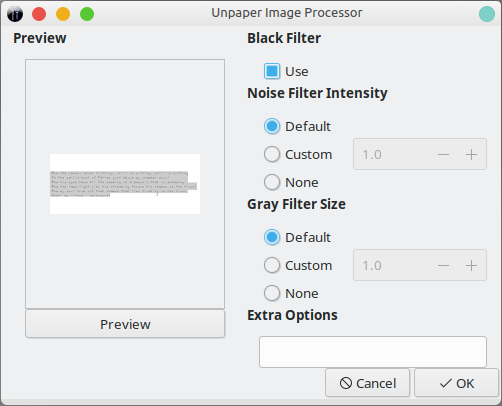
Deskewing & unpapering
OCRFeeder comes with two nifty functions - the ability to try to auto-rotate text in skewed image scans, and the ability to remove the paper background in order to reduce the noise and allow for a more accurate conversion. I tried both options, and Deskew worked just fine. Unpapering, so-so. But after I had the text rotated (which I did in GIMP in control images way back when), the results of the conversion were even better.
Export to ODT
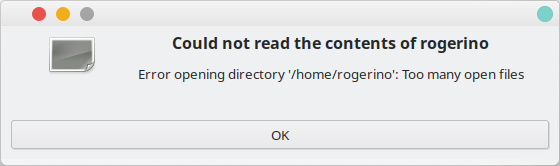
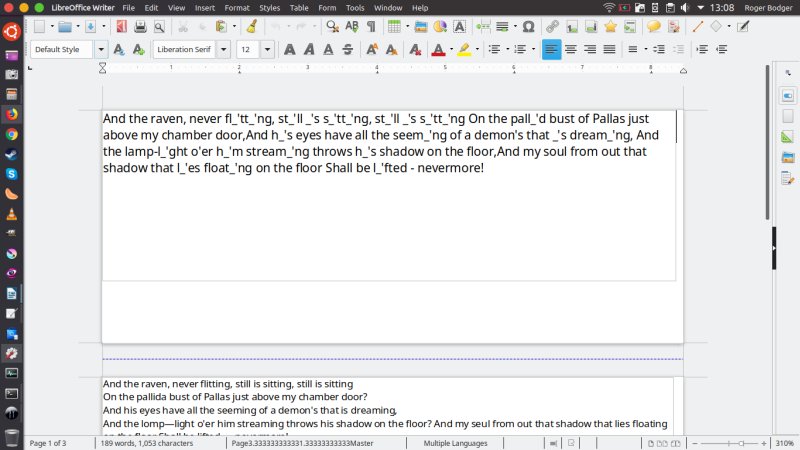
This was a bit tricky. I tried this a few times, and I hit a bunch of errors. Eventually it worked. The output isn't the prettiest, but the good thing is, you can export multiple conversions at the same time, including having used different engines for various images. Quite nifty.
Preferences
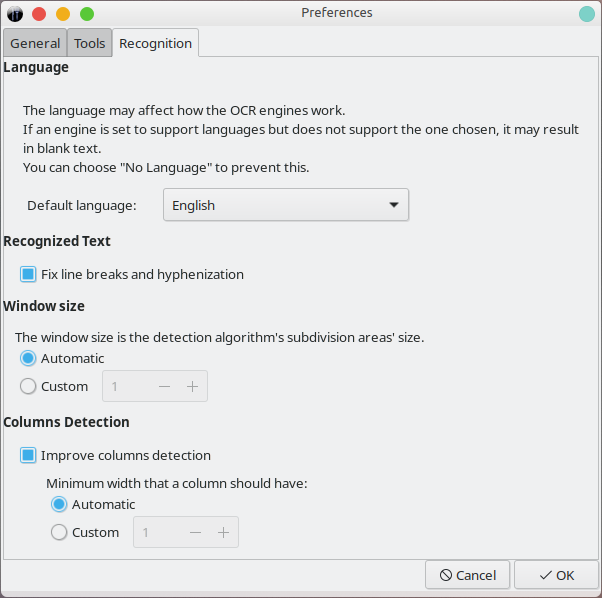
Finally, you have the option to change the behavior of the program. Nothing too major, but it can help with the detection and accuracy. Mostly it comes down to how you detect text column width, margins, language selection, and alike. For most people, the defaults will be a reasonable starting point.
Conclusion
OCRFeeder is a reasonable, flexible piece of software. It can use multiple engines, and the image-fixing algorithms are a nice addition. This makes OCRFeeder probably the most promising software of this kind on the free market, but then your hopes must be dashed right away, because it's unlikely to see an update any time soon, unless someone picks this up. Because there's market to be had in this, but the Linux world is stuck in a difficult position, between weariness and apathy.
That aside, age and updates thingie aside, for the most part, OCRFeeder delivered. The conversion quality wasn't bad, you don't lose anything by using a UI to do your work, and the export function lets you create nice documents for further editing and such. I am also happy with the improvements in Tesseract. So if you've got a bunch of text-happy images, and you'd like to try converting the hand-written text on ancient forms into something modern and usable, you could this. OCRFeeder supports PDF as well as reading directly from scanners. Well worth the experiment. Now time to go, bye bye.
Cheers.