Updated: October 16, 2020
My everyday disdain levels for most things earthly are often high, but throughout 2020, they rose exponentially. Ignoring the underlying phenomenon, 'rona, 2020 brought about a storm of populism and populistic science that made my statistical chakras shiver with fury. I have always known that people struggle with basic math, but oh boy, this year is truly special.
So I thought, the best way to vent all this anger is to actually write a nice little article that might explain some of the basics of data collection and analysis, scientific experiment and all that it entails, and the magical word statistics, which nowadays is wielded as a weapon of apocalyptic proportions. As it turns out, people make decisions based on statistics, right, without really understanding the numbers themselves or having those numbers actually be accurate and useful. Well, I'm here to help. Hopefully. Do read.

Note: Image taken from Wikimedia, licensed under CC BY-SA 3.0.
{kind=link}
A statistical idiot or statistically an idiot?
The answer is yes. The probability of you being either one of the two is very high. There's nothing inherently wrong with that. Even among people with higher education, including advanced scientific and engineering degrees, a good mastery of statistics is not a given. Primarily because statistics are quite often counterintuitive (e.g.: Bayes' Theorem, base rate fallacy), and also because the equations are tricky. Ask an "engineer" to explain and then manually develop a least squares method or perform a linear regression analysis on a data set, and they will struggle. Now, we don't even want to talk about things like ANOVA. Oh no.
Combine that with human laziness and not very high levels of intelligence (among general populace) to begin with, and there's almost no chance, or rather, should we say, there's a very, very, VERY low probability of helping an ordinary person actually understand statistics, or even the basic manipulation (not in the bad sense) of data. The problem is, statistics is used to manipulate data - in the bad sense. Hello politics!
The statistics of fear
Things become really complicated once "media" gets their hand on numbers and then weaves them into a frightening story of ifs and maybes, which to ordinary people are fatalistically certain and ominous - you don't need to cast your net far for examples, the ongoing boogaloo is a perfect scenario. For example, if a report says:
You are 80% more likely to die from disease B than disease A.
A common mouthbreather reading this piece of information will interpret it like this:
OMG, if I catch B, there's 80% chance I'll die.
Or better yet, because people don't really even know what percentage or chance really mean, then:
OMG, I'm dying.
This is mass hysteria in a nutshell. Welcome 2020!
Trying to make sense out of sensationalism
To keep the emotions at a bearable level, I will discuss a seemingly neutral topic - but the logic applies to pretty much any scenario. Let's say car accidents and fatalities. Let's examine a hypothetical scenario from a hypothetical country:
- In year X, there were 400 traffic-related fatalities.
- In year X+1, there were 548 traffic-related fatalities.
Now, let's say these are facts (fact-check!) - although this cannot be taken for granted either - we will touch on this in a moment.
What happens now is, let's say "media" reports this - you want the information to be newsworthy, ergo interesting, ergo shocking, controversial, appealing to the lowest common denominator of intelligence, passion and righteousness. Therefore, this translates to:
Road fatalities on the rise. 37% more dead!
The average low-IQ reader sees this and thinks:
OMG, I'll die on the road, why isn't the government doing something?!
The politicians see this too, they figure: let no crisis go to waste, Machiavelli, check, we need to do something! The famous "activity" syndrome, so brilliantly explained in Yes, Prime Minister, the finest political satire (or is it) of all time.
It's not about results, it's about activity!

Look at that smug little smile. The dude knew it.
Now, a year passes, we examine the numbers again, and we see a new result. Without even looking at the numbers, the conclusion is:
- The value goes down - This is thanks to the effort of the [favorite party/whatever], kisses, hugs, praise, votes.
- The value goes up - The public hasn't done enough. This is because [not favorite party/whatever], admonishment, rebuke, a call for more activity!
Of course, if you are capable of counting to 42 without getting confused, you probably think this is utter bollocks. But you would be astonished that this is how politics have been done since Ancient Sumer, give or take the context - they didn't have cars back then, just autonomously driven oxen and camels.
Why absolute numbers and percentages are meaningless
In the example I outlined above, the information presented is 100% worthless. Speaking of percentage, notice that when "media" reports various trends, they will almost always exclusively use percentage 0-100, but multiples above that value (e.g.: x2, x5, x33), again, because the ordinary people think:
ZOMG, like, you can't have more than 100%!
Thus, you are 30% more likely to be X, but 7x rather than 700% more likely to be Y.
Another reason is - if you write 700%, people may think something is 700 times more whatever.
So what should we do about the numbers?
The numbers MUST be normalized to make sense. This means translating absolute numbers into values that have a defined reference, so they can actually be calibrated (and compared). The very obvious thing would be to understand whether 400 is a LOW or HIGH number. How big is the actual population affected by these figures? Having 400 road deaths in a population of 1,000 people would be tragic, catastrophic; having 400 death out of a billion would be individually tragic, but meaningless in the overall scope of things.
Furthermore, there's the matter of statistical significance. From a purely mathematical perspective, this value tells us whether something we measure results from a deliberate change in the system or whether it's part of the system's "noise" - a level of randomness that may exist in the system.
To give you an example, let's sat you spill a bag of coffee beans on a floor. The beans fall in such a way that they spell out your name. If you look at the problem from the physics perspective, there's nothing that prevents this from happening. It's just that the probability for this is VERY LOW. If I may namedrop a little, from a physics perspective, the beans scatter can be "relatively" easily explained using the statistical mechanics, the concepts of canonical ensembles, or entropy.
Then, if you spill the beans a hundred times, you may discover that beans could tumble from 1 cm to
10 m from where you stand. This will tell you about the
distribution of beans, and allow you to create a mathematical model
that allows you to separate events that are part of the system's randomness and those that are results
of deliberate changes, like say whether instituting a new traffic regulation policy actually affects
the fatalities in a meaningful (statistically significant) way.
In our example, we don't know what kind of error we can apply to our annual data, in order to determine whether an increase or a decrease in the following years can be attributed to seemingly random variables that are not controlled, accounted for or easily quantifiable, or actually attributed to deliberately instituted changes.
This brings us to what constitutes a proper scientific experiment - and how it must be conducted, so that when you actually claim something (hypothesis), then you have a verifiable way of proving or disproving your claim. But that's for later. Let's go back to our numbers.
So, the numbers must be normalized. Trivial option: number of death per thousand.
But this is not enough. There are tons of factors that must be taken into account. For instance: the average driver age, the average driver mileage, the density of cars per km of road, the amount of sunshine, fog or snow in a year, the average ambient temperature, the type of roads, the quality and age of vehicles on the road, the stringency of the driving test and traffic enforcement, speed, and more. And then, you also need to take into variations for each one of these factors, understand their importance in the equation, and understand interactions.
This translates into an almost infinite number of permutations, which cannot be tested in a meaningful way, especially not in the typical timeframe that people expect.
Here, I must invoke another special term - statistical engineering.
This is my most favorite domain in the entire world - at least when it comes to numbers - and it offers a world-effective way to determine the important factors in multi-factor setups with complex interactions. I've been using it throughout my career with great delight and awesome results, and it features in every technical book I've written. Alas, as rare as the knowledge of statistics is, the mastery of statistical engineering is even rarer. Sad face.
Back to our numbers ...
Say, if we develop a system that accurately accounts for 10+ most important factors related to traffic road accidents and deaths, and we also understand what constitutes a meaningful change (say standard error, known distribution, etc), then we can actually look at the numbers in an accurate way.
But ... we didn't talk about the collection of numbers and whether the "raw data" we have is valid.
We assumed that 400 and 548 are accurate numbers.
This is another problem that goes beyond statistics. It's the validity of data, and by proxy, the validity of the "experiment" - the method by which data was sampled, collected and analyzed against the original hypothesis.
We do not know if the two values - 400 and 548 - have been measured against the same set of criteria. For instance, what constitutes a traffic-related fatality? Does it include pedestrians or cyclists? Does it cover rural roads and industrial accidents? Has the criteria for classification changed in the past year?

If you drive really really really fast, you progress a greater length of road every second than if not.
If the answer is yes - something in the measurement, collection and classification of data has changed - then your experiment becomes invalid. Comparing data that result from DIFFERENT experiments is wrong. Specifically, this is why comparing road accidents across countries is often problematic. You can't compare the road figures from Mongolia with those of the Netherlands. You can't even compare Spain with Finland, even though both are developed countries in the EU.
Then, one may assume that when you do studies for large, seemingly random populations (like countries), the various anomalies even themselves out, and you're left with credible information. This may be true, but it can also be very wrong. Going back to our previous example, it could be that the increase in year X+1 results from better reporting, or from just two extra accidents involving buses, or from a major infrastructural project in a part of a country, or from a change in the traffic laws. Without accounting for these, trying to "fix" a problem will lead to arbitrary results.
Proper scientific experiment
So if you want to talk about numbers, then those numbers must be accurate, and that means, first and foremost, you need to adhere to the rigors of scientific experiment. This is very important.
- Observe a phenomenon (tricky in society for most part, but doable with a lot of effort) - the observations must be done with a strictly defined criteria, e.g.: there must be precise, deterministic definition for any observed event. You can't just wing it.
- Propose an explanation for the phenomenon - the first step to anything. If you do not understand a phenomenon or what causes it, it is hard to control it or change it.
- Define the method by which you will test your proposed explanation, i.e. you will do something and that something will trigger a change in the phenomenon. This effectively becomes your experiment. This must be done in advance.
- Define the success criteria for your experiment - similarly, you must do it in advance, i.e. not collect random data any which way and then try to find a correlation or explanation retrospectively. This is super important, so you do not fall prey to your own confirmation bias. There's nothing wrong in an experiment that returns negative results, i.e. makes your initial hypothesis incorrect. Excellent. You can now think of a different proposal that explains the observed phenomenon.
- Conduct the experiment without changing the rest of your experiment setup (system) - this is a controlled experiment. If other conditions or variables change, then your experiment becomes invalid. For example, if you want to see whether the introduction of new speed limits changes the number of road accidents in some way, that ought to be the only parameter in the system that changes. If you suddenly introduce more frequent police patrols and increase enforcement, or perhaps divert heavy traffic (trucks) to dedicated roads that are not shared by everyday commuters, you change the system, and results of the experiment will not reflect what you set out to test.
- Analyze the collected data against the success criteria. This is not trivial. The analysis needs to be: objective, unemotional, strict. If you get results that disprove your hypothesis, great. Accept it and move on. If you feel tempted to change the data or the analysis methods at this point, don't. You will invalidate the experiment. Again, this emphasizes why the method and success criteria MUST be defined in advance.
Data analysis ...
Data analysis is a complex subject. Even if you do all the steps in your experiment right, you can still make tons of mistakes in the actual analysis and interpretation of data and results. One, you cannot just randomly apply equations if you don't know what your data looks like. Distributions matter. A great example for the importance of proper understanding of data is Anscombe's Quartet - which I discuss in Chapter 8 of my problem solving book, btw - which highlights the issue in a very clear, clever way. Simpson's Paradox is another example where blindly applying equations leads to the incorrect interpretation of the results.
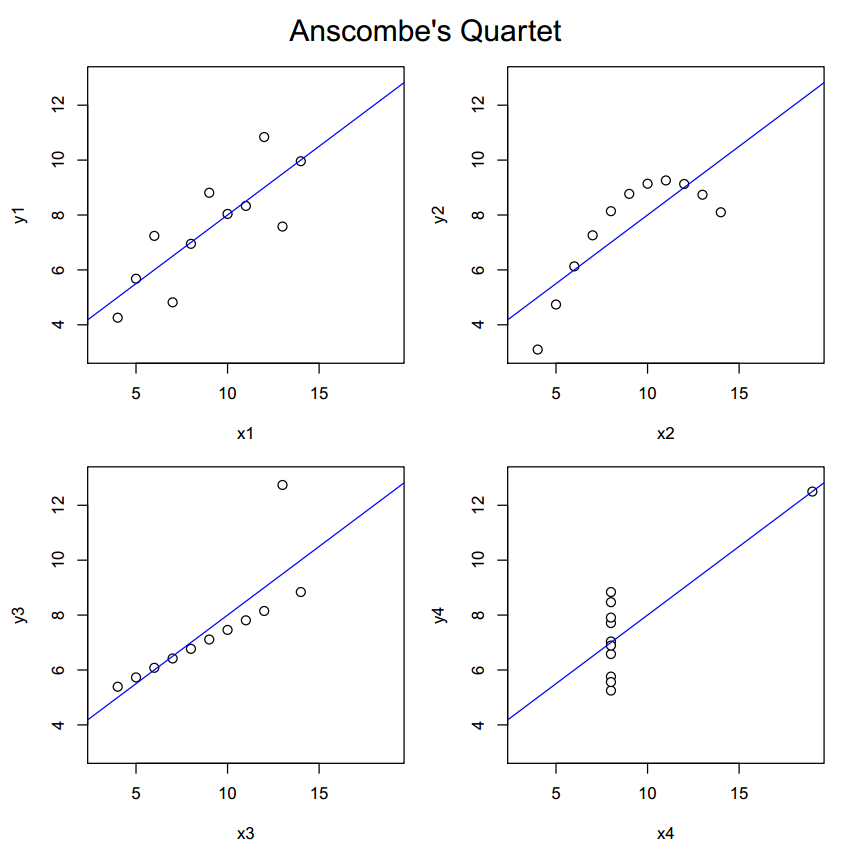
You may be tempted to discard or ignore data as insignificant, but this can only be done if the mathematics agree. There are very strict definitions to outliers with different distributions of data sets, and there is no room for emotion here whatsoever. This is where confirmation bias may creep in and destroy our logical thinking.
The scientific community is well aware of the issue of logical fallacies that affect us as humans, which is why there are additional safeguards, like blinded experiment, peer review, a combination of these factors, and more. Even so, when there's massive public pressure for specific outcomes, it can be extremely difficult to conduct scientific experiments in perfect, pure isolation.
Let's do some drama
Since this article is too technical, boring and not controversial enough, I want to address one of the popular modern topics - human-caused climate change (formerly known as global warming). One of the reasons, but not the only reason, why this is such a controversial area is the complexity of the system and how the "experiment" is being done.
Technically, we have direct data measurements from around 150 years (or less), plus indirect results going back millions of years. The data from the recent past is an observation, which can then be used to propose an explanation - the human effect on the climate. So far so good. However, the two things missing from this equation are the success criteria and the ability to conduct the experiment without changing the system.
Furthermore, the world is a dynamic place. Our presence on the planet is constantly changing, including the effects we generate in the environment. Then, governments have already introduced measures designed to reduce the effects on the environment (like carbon emissions) - but this is the very thing that our experiment requires to remain unchanged (in the experimental sense) for us to be able to ascertain whether our hypothesis is correct.
Ideally, we would let the experiment run unchanged for a while - but the problem here is (also) twofold. One, we do not know what the system latency is, i.e. how long it will take for the system to respond. For a system like the planet's climate, we are talking decades if not centuries or longer. That is a very long time by human standards, way beyond interest or patience of any political group, and a challenging proposal for people who might be affected by the (negative) changes in the climate one day, if the proposed hypothesis is correct. Two, because of the associated risks, there is little to no desire to let the experiment run unchecked - which undermines its scientific nature, as it assumes conclusion without the full sequence of what is required to verify the hypothesis.
Since the success criteria is not defined (the system is too complex really), if the results diverge from a proposed explanation, one (say a savvy politician) could always say that "we didn't do enough" - on the other hand, if the results agree with the proposed explanation, or even turn out to be "better" than estimated, then one could always say that "adverse effects on the planet's ecosystem were forestalled by diligent action", irrespective of the underlying mechanism. While this may be a good thing overall, it undermines the scientific nature of the process - and also limits our understanding of the system, which in this case would include all the unaccounted factors - like say Milankovitch cycles, to name just one. Large-scale simulations help, and you can use supercomputers to crunch millennia worth of data, but we still don't have a precise model.
Lastly, keeping measurements precise and accurate and unaffected by the surroundings over 150 years is very hard - for instance, due to urban creep - or by any change in the measurement methods and data collection, all of which would invalidate a classic experiment. The combination of the political message, the non-strict nature of the experiment, and the veracity of the data create an environment [sic] that casts a shadow on the purity of science involved.
Then, there's the whole socioeconomic dimension, but that's not our topic.
Statistical engineering
Now, now, in some situations, you may not have sufficient data to even understand your system well enough to propose an experiment, either because the system is too complex, or you haven't interacted with a system long enough. For instance, you may want to know which component (software or hardware) in a data center server equipment is (or will be) the primary contributor to the runtime performance of your applications.
In a case like this, a classic experiment would be something like:
- Components to check: physical memory type and size, hard disk type, CPU type, operating system.
- Levels to check: the simplest experiment would be to select two levels for each component, classify them as low or high - which would mean low performance and high performance - assume linear interaction between the two levels, and then run your experiment by testing every possible permutation.
If we assume just four components and two levels, there are 16 permutations to check (2^4). If you have say seven components and four levels, the classic experiment soon becomes infeasible (4^7), because no one can run hundreds or thousands of experiments in a practical way. And it may very well be impossible to properly analyze interactions.
This is where scientific engineering comes in. Scientific engineering is all about Y->X rather than X->Y, which is the classic experiment. Scientific engineering focuses on the analysis of variances - figuring out the most meaningful contributor to the system, even if you do not yet fully understand the system and all its interactions. This simplifies the setup - from power to log - you basically need to run components x levels tests.
- Going back to the server example, you select one component (say disk type), you leave the rest UNCHANGED.
- You then run your experiment for each defined level - say two (HDD and SSD). You check your application performance.
- You repeat for other components, one at a time, while the rest remain unchanged.
- What you're looking for is the variance between results. The component that contributes the most is the primary factor.
From this experiment, you will determine the most important contributor(s) to the system. Now, this can be considered an initial observation, and from here on, you can now reduce the complexity of your experiment to a small, controllable set of variables. For instance, a statistical engineering experiment may show that the CPU is the most important component. Now, if you want to improve the performance of your applications, this is where you focus your effort. You propose an experiment ... and you know the rest.
Back to our numbers, again ...
What we have so far:
- We know that numbers on their own are meaningless - they must be normalized.
- We know that we must account for the measurement methods - otherwise, we could be comparing mangoes and plums.
- We know that if we want to change the numbers (reduce the number of fatalities), we need to understand the system.
This means making small, isolated changed to understand the contribution to the overall result - and that means only changing one parameter at a time. Not an easy thing to do when the numbers are mired in political popularity and high social impact, right. But it is the RIGHT thing to do, because that allows us to understand what actually causes the fatalities in our fictional scenario.
In essence, on a country level, this would mean introducing experimental enclaves - where one of the many possible parameters is changed while the rest remain as they are - speed, car density, road quality, road illumination, seasonal patterns, etc. Only then, can we propose meaningful activities - and test them of course, fully aware of the risks involved.
Alas, impossible when science and politics mix.
No one wants to be the politician accused of "neglecting" or "playing with" human lives. No one wants to be the possible fatality of an "experiment". When I say no one, I mean the people who panic when they read 37% in the newspapers. It's a self-feeding, self-defeating cycle. Because real science is too boring and too complex, the public-facing information is 99% overhyped bollocks, which is then used as a tool of propaganda to generate activity (and publicity) among politicians, and then amplified by media, and then - here comes the paradox - used as the vengeance tool against politicians when things go wrong or not as well as expected (often when there's no proper science involved).
BTW, when things go wrong, people blame the "science" for being wrong - and not the politicians or media for cropdusting bullshit all over the place, and this leads to general mistrust of scientific findings. This is another self-feeding and self-defeating cycle. Because it is virtually impossible to separate pure science from politics, science becomes tainted, ergo the system changes, and thus, the ENTIRE experiment becomes invalid. And this case, the experiment is the validity of science itself as a tool of advancement of humanity.
Which is why "science" is often used as a scary klaxon, and then the only really practiced method is "best safe than sorry", leading to arbitrary decisions and meaningless changes in the society with powerful long-term ramifications. Welcome 2020.
This is why, going back to the road traffic, many countries have speed limits that do not necessarily reflect the reality of driving. But it's an easily observable, easily quantifiable, easily explained, and easily publicized change, even if the results may not agree.
And this is why people who actually CAN do numbers are often distrustful of media-hyped figures and statistics, because they do not represent accurate results from properly conducted scientific experiments (in the wider sense of the word), but rather represent easily digestible, populistic bits that instill fear in the common populace, and very often are tainted with political bias or even direct financial involvement by interest groups.
Consensus
People are tribal animals. We create tribes all the time - and we seek validation for our choices from the members of our tribe(s). Some tribes can be very small - like the family cell, while others can be large, like say fandom of a pop star or a sport club. However, our tribal nature is the complete opposite of what science is all about.
Science is not some bullshit college debate. Nor is it a democracy. A thousand wrongs does not make one right. If you conduct an experiment, get a result - and then someone else gets the same result, great! You both could be wrong! Or right! Having multiple, independent experiments agree on the same common theory usually means there's less chance of your idea being wrong, but ...

"You are all individuals." -Brian. "We are all individuals." -the crowd.
Most experiments are not independent, and ideas are often tainted by "intellectual osmosis", as people with like-minded interests share like-minded thoughts and data, and reinforce one another's biases, for better or worse. Throughout history, there have been countless examples that had a "consensus" agreement, and which turned out to be utterly false. To name just a couple of random examples, for a long time, it was believed that ulcers were (primarily) caused by stress, which turned out to be wrong. Then, you have the shitty eugenics theories that were so popular in the first half of the 20th century.
On the other hand, the research on the photoelectric effect is a great counter-example. It won Albert Einstein a Nobel Prize - contrary to what most people think, he didn't win one for his work on general or special relativity. But I'm digressing. The important thing here is that Einstein came with his hypothesis in 1905, and it took a while (several years) before his predictions could be empirically proven correct, and there was a rather significant resistance to his ideas. Consensus didn't change the reality. Quantum physics doesn't care for human thoughts.
It is very hard for humans to disassociate their innate need to belong - because science requires an isolated, independent approach to the experiment. Not easy to achieve under the best of circumstances, let alone when there's immense non-scientific pressure for specific results.
Science as a religion
For thousands of years, religion has played a huge part in the lives of people, across cultures and territories. The massive advancement of science in the past 200 years or so has eroded classic adherence to religion in some part of the world, but it has done nothing to change the human psyche. Which is why lots of people simply trade the concepts of religion for science without any fundamental change in their thinking.
Some of the phenomena include:
- Science becomes absolute - right or wrong (whereas the debate should be: I need more data).
- Science is wielded as a magical scepter, and you must accept it without fail. Skepticism in not a possibility.
- Scientists are treated as priests, and their word is sacred (or heretical for that matter).
- Adherence or rejection of any "scientific" idea evokes a dogmatic emotional response.
- Ordinary people expect science to render miracles, and when it doesn't, they either ignore it or reject it as a false creed, or if they reject it to begin with, the results reinforce that rejection. When people expect experiments to "disprove the nonexistent" - things become even worse.
Unfortunately, this is true both for people who reject most of the scientific theories as well as those who embrace them. Rather than treat science as a complex field, with a neverending sequence of experiments (most of which turn out to be wrong, btw), science is reduced to nothing more than a binary choice - yes or no, for or against.
If you think I'm being sensationalist, just take any which popular topic - including the 2020 favorite, 'rona - replace the topic words with classic religious terms, and you will see that science plays no part in the equation.
In fact, let's illustrate. I am going to paste below a redacted snippet of a topic from Wikipedia, which revolves around some of the ideas we mentioned earlier. Now, please note, 'tis just an article, it's not an official anything, and anyone can edit and contribute their thoughts and opinions. Nothing wrong with that. But in many cases, for ordinary people, that could very well be the one source of information that they reference, if any really. As such:
X denial, or Y denial is denial, dismissal, or unwarranted doubt that contradicts the scientific consensus on X, including the extent to which it is caused by humans, its effects on nature and human society, or the potential of adaptation to X by human actions. Many who deny, dismiss, or hold unwarranted doubt about the scientific consensus on X self-label as "X skeptics", which several scientists have noted is an inaccurate description. X denial can also be implicit, when individuals or social groups accept the science but fail to come to terms with it or to translate their acceptance into action.
First, the mention of "unwarranted doubt that contradicts ..." The motivating force behind science is doubt, or rather skepticism, which itself is rooted in curiosity. If you do not challenge the existing conventions and theories, then you can't really propose any new ideas, and there can be no progress. Doubt is not a negative quality. It is a self-checking mechanism that helps us improve our chances of survival, on every level.
Second, there's the "activism" part - where not only are you not supposed to have an opinion that contradicts the "consensus" - you are also supposed to translate this acceptance into action. Basically, public rituals. Let's ignore for a moment that most people don't have the tools to understand the actual scientific problem at hand to make the right decision on what they "should" do. But hey, if you're not for, then you're against! No middle ground!
Third, to further hammer in the point, the article has a pie chart that shows "percentages" of several studies into scientific agreement on X. Once again, science isn't some fireplace debate, and consensus is irrelevant. What matters is whether the data is accurate and the results of the analysis agreed with the proposed explanation based on the agreed experiment methods. Everything else is touchy feely nonsense.
What should an ordinary non-expert person do then?
TL;DR: keep vewy vewy quiet.
For some reason, most people feel they should get involved in things, even when they have very limited understanding of what's going on. When it comes to science, things get extra tricky. I have spent a lot of time trying to find a simplified formula by which one should judge whether they are qualified to participate in any discussion on scientific topics - and specifically, statistics.
I may be wrong, but I think I found it. This may sound weird or extremely arrogant, but hear me out. The answer is: Partial Differential Equations. If you do not know what they are or what they do, then most likely, you are not going to be very good at analyzing numbers, and/or you are going to draw wrong conclusions based on your interpretation of data.
Now, the inverse does not mean PDE knowledge = good data crunching skills. Far from it. You see!
But what the above tells you, if you don't have any idea what I just wrote, whenever numbers are discussed, whenever the statistics are invoked, whenever you need to figure out if the numbers "tell" you what you expect to know, just don't. As tempting as it is to go on social media and talk nonsense, simply don't.
Some practical tips after all
I ought to summarize a few things I've written here, so that you do end up with something tangible and practical:
- Statistics are often counterintuitive.
- You need a strong foundation of mathematics to be able to master statistics well.
- Statistics published in popular media are often useless as they do not provide the necessary context. They are designed to garner readership not foster scientific curiosity.
- Percentages are often useless.
- Absolute numbers are often useless.
- Numbers need to be normalized to a well-defined reference scale.
- Numbers are useless if you do not understand the system.
- Numbers cannot be compared across multiple, different systems.
- A proper scientific experiment requires a hypothesis, method, tools and results defined in advance.
- If you change the system while running your experiment, your experiment becomes invalid.
- Statistical engineering is an excellent tool to form an understanding of complex systems.
- Politics and science do not mix well - avoid.
In the end, this article will be useless ...
The biggest problem with everything I've written is that it will make zero difference in the world. Zero. Those who agree will nod smugly. Those few who understand numbers and feel there's erosion of integrity in scientific data and reporting will probably draw some solace that they are not alone and isolated in their thinking. Those who don't care about data or science or statistics will never ever see or read this article, as they have better things to do, like update their social status or get scared by the news.
I am fully aware of the futility of my effort here. True change can only be a result of strong, science-focused education over generations. Not two or three or five years, but generations. Decades. Much longer than the typical tenure of any which politician in the office. Which is why our (human) future is not going to be any easier or more logical. As science gains more and more importance in our daily lives, as numbers and data become more prevalent (and also more difficult to digest and analyze), so will the friction between science and politics grow.
Individually, the only thing we really control is ourselves and our understanding of the environment. And that also means being able to make sense of statistics when they are presented to us. And that means doubt. Not distrust - doubt. Not taking numbers and figures at face value, but rather making sure that we fully understand the system and the experiment that have produced those numbers and figures. Otherwise, we lose control. And when you realize how dumb the average mouthbreather is, and what that implies, you sure don't want to be part of that statistic, now do you?
P.S. The images of Niccolo Machiavelli and the sheep are in public domain.
Cheers.