Updated: March 27, 2017
So here's an interesting story for you. A story with a happy ending. One that could have ended up in tears, but it did not, as it builds upon a solid foundation of data backups and system imaging. On the same day I was fighting a corrupt EFI partition on my test laptop following a botched Solus installation, wifey told me she couldn't save files to a folder on the E: drive on her Windows box. That didn't sound good.
I quickly examined the situation, and one of the Western 1TB Blue hard disks inside the desktop tower was rapidly growing the number of its bad sectors. This hard disk had three partitions on it, C:, D: and E:. Oops. A quick Internet search suggested running chkdisk and trying a few other hacks to keep the disk alive for a while longer, but the situation was deteriorating fast. At first, it was only the E: drive gimping, but then the D: drive joined the party. There was no need prolonging the inevitable. It was time for a change. Cue in Scorpions, Winds of Change. Play it while reading this article.

Note: Image taken from Wikimedia, licensed under CC BY-SA 3.0.
{kind=link}
Drama unloaded
Before I tell you what I did when the problem started, let me briefly outline what I did BEFORE it happened. I have an extensive backup strategy that I have maintained for the last 8-9 years. In that period, my various backup tools and utilities have copied over 7 PB of data across a dozen different internal and external hard disks, all in order to ensure there's sufficient data integrity in place. And this is excluding offline and other types of backups. Also, the operating systems are frequently imaged, using Acronis True Image and Clonezilla. In fact, almost acting on premonition (or genius), I imaged the operating system less than hour before the incident.
When things started going badly, the Windows disk management utility reported less-than-actual usage of the filesystem on the E: drive and then also on the D: drive. This was a sure sign of things escalating, as which point it was time for some urgent medevac. It is important to emphasize that, in addition to daily backups and up-to-date operating system imaging, I also have spare hardware in place. No screenshots from the time of the incident, because I was actually busy working.
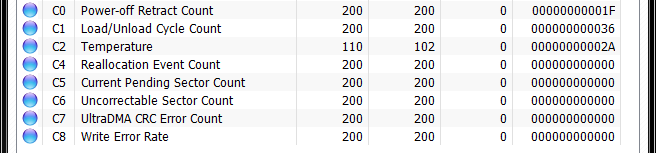
If the blue changes to red or yellow, bad things are about to happen.
I powered down the desktop, opened the case and replaced the dying 1TB Blue with a 2TB Black. I then powered on the desktop and booted into a live Ubuntu 16.04 session from a thumb drive, where I used the GParted to create the necessary partition layout. I created the 100MB System Reserved primary partition, and a 110GB partition as a destination for the operating system. The original Blue had a 100GB partition, but I thought it would be better to ever so slightly increase the size to avoid any chance of image recovery failing. Lastly, I created the extended partition, to include the two logical partitions corresponding to the D: and E: drives, with the associated increase in size.
Once this step was complete, I booted into the Acronis live recovery media and restored the MBR, System Reserved partition and the C: drive. Everything completed successfully. I did mark the C: partition as active, which turned out to be a mistake, and on next reboot, the desktop complained about not being able to find the bootloader. This necessitated another Ubuntu live session, where I changed the partition flags using GParted. After this, Windows loaded fine, as if nothing bad had ever happened. I also restored the data to the two drives D: and E:, and within less than one hour total downtime, I was back to normal production.
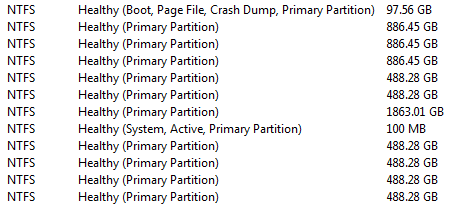
Make sure you set boot flags correctly.
The one outstanding activity was to run chkdisk on both data partitions to make sure the filesystems are fully consistent, and that whatever partitions GParted created work fine in Windows. At first glance, everything is peachy, but should anything prove to be wrong, a quick re-format and data restore are in order. However, I believe this little incident is over. Until the next disk failure. Which WILL happen. And you just have to be prepared.

Conclusion
Disk failures are not the matter of if but when. You MUST plan for them. It's the only way you can ensure the integrity and safety of your data. You must have multiple backups in place, and you must be ready to restore at any point. You should also have contingencies when it comes to the operating system - and hardware. It may cost money, but if you care about your production setup, then you'd better invest. Because the alternative is frustration, tears and maybe even worse.
My example is just one of many stories floating around the Web. Hopefully, it's a story you will hopefully find valuable, as it highlights the merits of a combat-proven setup, with the necessary resilience to allow a near-seamless restore back to normal conditions. This is not the first time I had to do this, and I'm glad I planned well.
I had spare disks, up-to-date system images and data backups, and I was able to recover quickly and almost painlessly. The disk replacement was the most arduous of tasks. And waiting for the Acronis DVD to boot. Losing a hard disk can cause people a lot of grief. I'm happy my setup withstood the test. Perhaps there's a worthy lesson for you in here. Stay sharp.
Cheers.