Updated: April 27, 2011
If you have lots of scanned documents that you plan to convert to actual text, you will need to use Optical Character Recognition (OCR) software. As the name implies, such software identifies letter shapes and patterns and translates them into text.
In Linux, we tried Tesseract, a free command-line OCR engine and program. It worked well mostly with high-contrast print, including rotated images, but it struggled with curvy, freehand-like scripts. Another limitation was the command-line use against indexed 256-color TIFF images. It did its job, but it wasn't too easy to use, especially for less skilled people. All right, but what about Windows? Several weeks ago, I was contacted by ABBYY marketing and asked to review their FineReader 10 Professional OCR software.

Download & installation
ABBYY FineReader 10 Professional is a commercial, payware product with a handsome price of 139 Euro for a complete version, 99 Euro for an upgrade, although you can subscribe for a short trial. The software runs on Windows XP through 7 and comes as a hefty 400MB download that grows into a 650MB installation. It's definitely not a lightweight program.
In return, the program promises high-fidelity conversion of images, including digital scans. FineReader allow multi-core processing, it works with 168 languages, it can export its output in numerous formats, and it can be trained to learn text.
The installation went smoothly. It took a while, but completed without any problems on a Windows 7 SP1 Ultimate edition. If you choose the Custom Setup, you have the ability to select what features to install, including recognition languages, integration with Microsoft software, the User guide, and the screenshot reader.

You can also choose to run the program at system startup and send anonymous settings to the vendor, which ought to help them finetune their engine for better recognition.

Once the program is installed, you will need to input the serial number and activate the product. There are many activation methods, including online, by email, by phone, or by loading your existing license. You can also register FineReader to receive technical support and updates. I do not know whether the activation and registration bind the software product to a specific computer and how many reinstalls are possible, if at all.

Using FineReader
The main window loads with the common tasks displayed, which include digital scans to searchable PDF and regular images, working with Adobe PDF software, and others. If you already have images ready for OCR translation, just hit Open.

To be able to test FineReader in a real-life scenario, I used the same control images like with Tesseract. This allowed me to compare the two products, in addition to checking the basic and advanced functionality of FineReader itself. Requoting myself, splitbrain.org did a very thorough and detailed Linux OCR Comparison, and it kind of served as the baseline for my own work here. In fact, I used some of the images Andreas used in his own article, so I could have a control group.
The control images are all 300dpi, in .png format:
courier-black-300.png (23.8KB, Andreas' image)
{kind=link}
justy-black-300.png (29.6KB, Andreas' image)
{kind=link}
courier-black-300-rot.png (14.7KB, above courier-font image, randomly rotated)
{kind=link}
Now, let's see the results.
Results
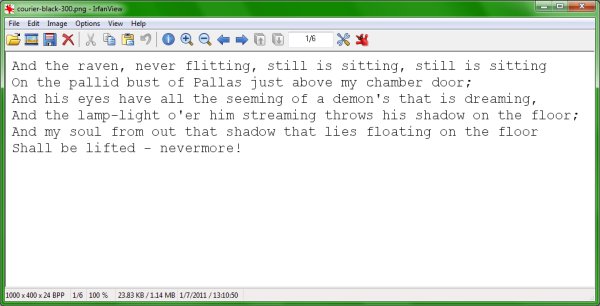
I first loaded the courier black font image. FineReader displayed the image just fine, but it did warn about the small resolution. The popup is alarming and misleading, because it reads error in the titlebar, when it's only a warning. Furthermore, FineReader completed the task successfully, so this could confuse users. Moreover, 300dpi image measuring 1000x400 pixels is not that small.

The processed images are loaded into separate pages, displayed in a two pane window, with the image on the left and translated text on the right. The layout is simple and easy to use. This is a far cry from the command-line use we saw with Tesseract.

You can manipulate images by rotating and resizing. Moreover, you can check errors in translated text and run spell checks. For my first image, the fidelity of the translation was spotless, with every single word translated perfectly.
Here's the original:
And here's the text:

Next, I tried the rotated file. FineReader struggled with this kind of image, displaying only a handful of unintelligible characters. I believe you must manually transform your image rotation for FineReader to work properly, but this could pose a problem with old documents that feature snippets of text from multiple sources pasted together in a haphazard fashion. Normally, human text follows either a horizontal or a vertical direction, but you might encounter cases where any additional processing would further erode the fidelity of the original.
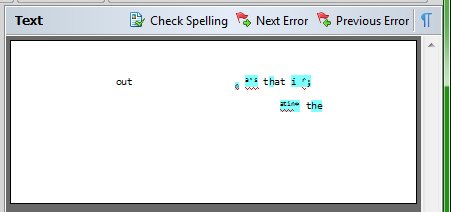
Lastly, I tested Justy, a wavy manuscript on a low-contrast gray background. Tesseract did not quite manage this one. Here, FineReader surprised with a decent, if not perfect translation. Far from the 100% courier result, but still reasonable. The program mostly struggled with the h later, seeing it as capital W. Letter t was perceived as number 4, but the translation was consistent throughout.
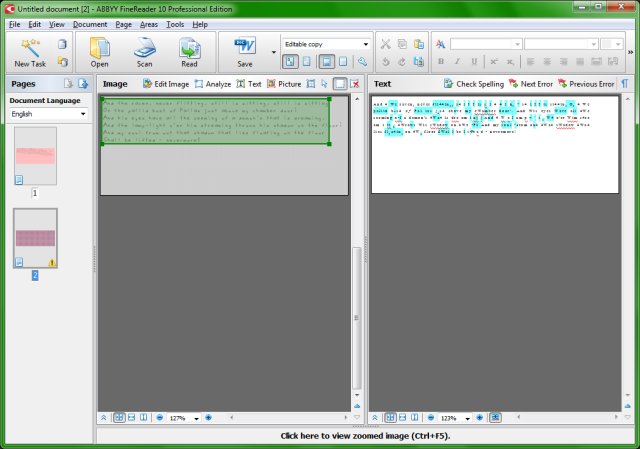
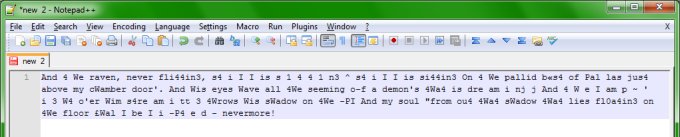
So far, FineReader was behaving well. It worked superbly with simple print on a plain background. It managed ok with wavy fonts and low-contrast background. It failed miserably with rotated text. These results bring me to the important point of software training.
Training mode
FineReader can be taught to recognize tricky forms in order to improve the quality of character recognition. Browsing through the help guide, I easily found what I needed and setup a short learning session.
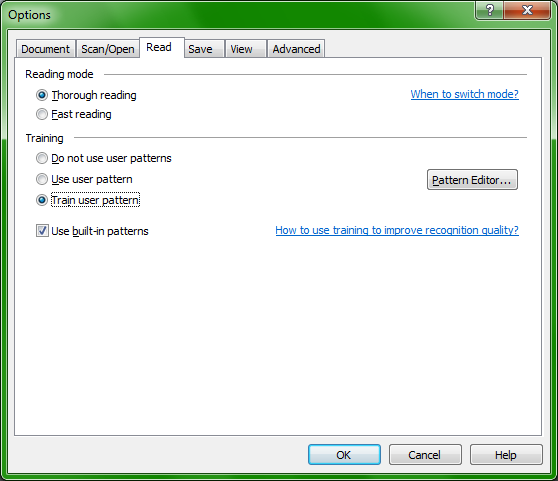
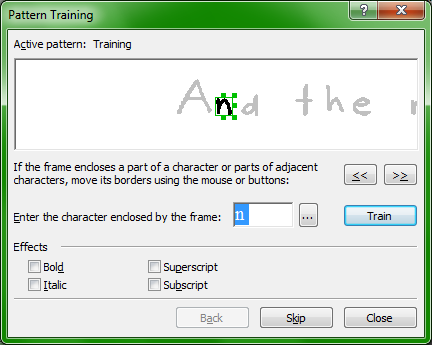
The one problem with the training is that it is long and boring. Moreover, FineReader sometimes identifies parts of letters as whole letters. What do you do then? Do you choose the whole letter, which is what I did, ending with some duplicates in your final conversion, or do you somehow ignore these snippets?
Here's my final result. Too many duplicate letters, but this could be my fault during the training. Still, after about five minutes of work with the justy font, I had this translation, which is significantly better than the original attempt.

Other options
FineReader has many options. In fact, it might be even a little intimidating for less skilled users. If you go through the menus and options, you will find a wealth of resources and functions. One of the big bonuses is the huge number of available languages. You can also use Microsoft Word custom dictionaries.
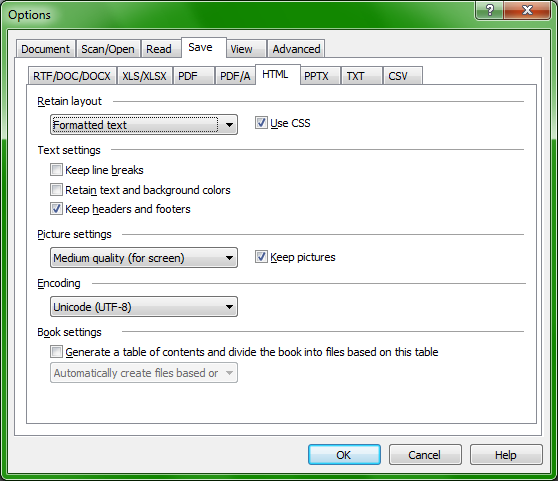
In the Options menu, you will find tons of other features, like the ability to save scans as HTML files, including CSS, set picture quality and text encoding, export to Word, Excel and Powerpoint, PDF, tagged PDF, text, and comma-delimited files. You can also use encryption.
Conclusion
Let's see the good things first: FineReader works well. It is fast and stable and the interface is fairly simple to manage. It supports a ton of languages and multiple image formats. The training mode can significantly improve the quality of the output. You have lots of export options available. Most importantly, the conversion quality is quite good for well-oriented scans.
On the negative side, the program has a big disk footprint and a very big price tag. It also throws some minor warnings that could confuse the user. The abundance of features acts as a double-edged sword and could frighten newbies. FineReader did not manage rotated images well.
To sum it up, FineReader is a very powerful program. Its killer feature is probably the language set, combined with good translation quality for plain images and lots of import and export options. The program can cater to newbies and advanced users alike. That said, I would like to see fewer spurious error popups and a better conversion of rotated images.
Now comes the tricky part. Should you buy this software? If you can afford the lofty sum, then sure, by all means, go ahead, you will enjoy using it. But in the age of a would-be recession, 139 Euro is not something you scoff at. Well, I guess that would be all. From the purely usage perspective, FineReader gets 9/10. As to whether it can justify your budget expenses, I leave the uncertainty entirely up to you.
Cheers.